Requirements Engineering
Check Your Requirements Quality with One Click – Everywhere!
By Michael Jastram
/ 28/01/2022
Checking the quality of requirements is not just useful. Considering the complexity of modern product development, bad requirements can easily...
Read More

Qualicen Snapshot – Ausgabe 2/2021 [in German]
By Silke Müller
/ 09/12/2021
Liebe Freunde und Freundinnen, liebe Partner*innen von Qualicen, das Jahr 2021 neigt sich langsam dem Ende. Hier kommt nun noch rechtzeitig...
Read More
![Qualicen Snapshot – Ausgabe 2/2021 [in German]](https://www.qualicen.de/wp-content/uploads/2021/12/Cover_Snapshot_2-2021.png)
Agile yet Safe! – System Testing in Agile Projects (in JIRA or Azure DevOps)
By Henning Femmer
/ 01/09/2021
Testing plays a central role in agile software development. We usually have unit testing and test automation under control. System...
Read More
Qualicen Snapshot – Edition 1/2021 [in German]
By Silke Müller
/ 31/05/2021
Liebe Freunde und Freundinnen, liebe Partner*innen von Qualicen, es ist soweit: die zweite Ausgabe unseres Snapshots - die erste im Jahr...
Read More
![Qualicen Snapshot – Edition 1/2021 [in German]](https://www.qualicen.de/wp-content/uploads/2021/05/Cover_Snapshot_1_2021.png)
Presenting to You: Qualicen Snapshot [in German]
By Henning Femmer
/ 17/12/2020
Liebe Freund*innen und Partner*nnen von Qualicen, Langsam schaffen wir es nicht mehr uns mit allen Kontakten regelmäßig persönlich auszutauschen. Und manche/r...
Read More
![Presenting to You: Qualicen Snapshot [in German]](https://www.qualicen.de/wp-content/uploads/2020/12/Bildschirmfoto-2020-12-17-um-10.45.54.png)
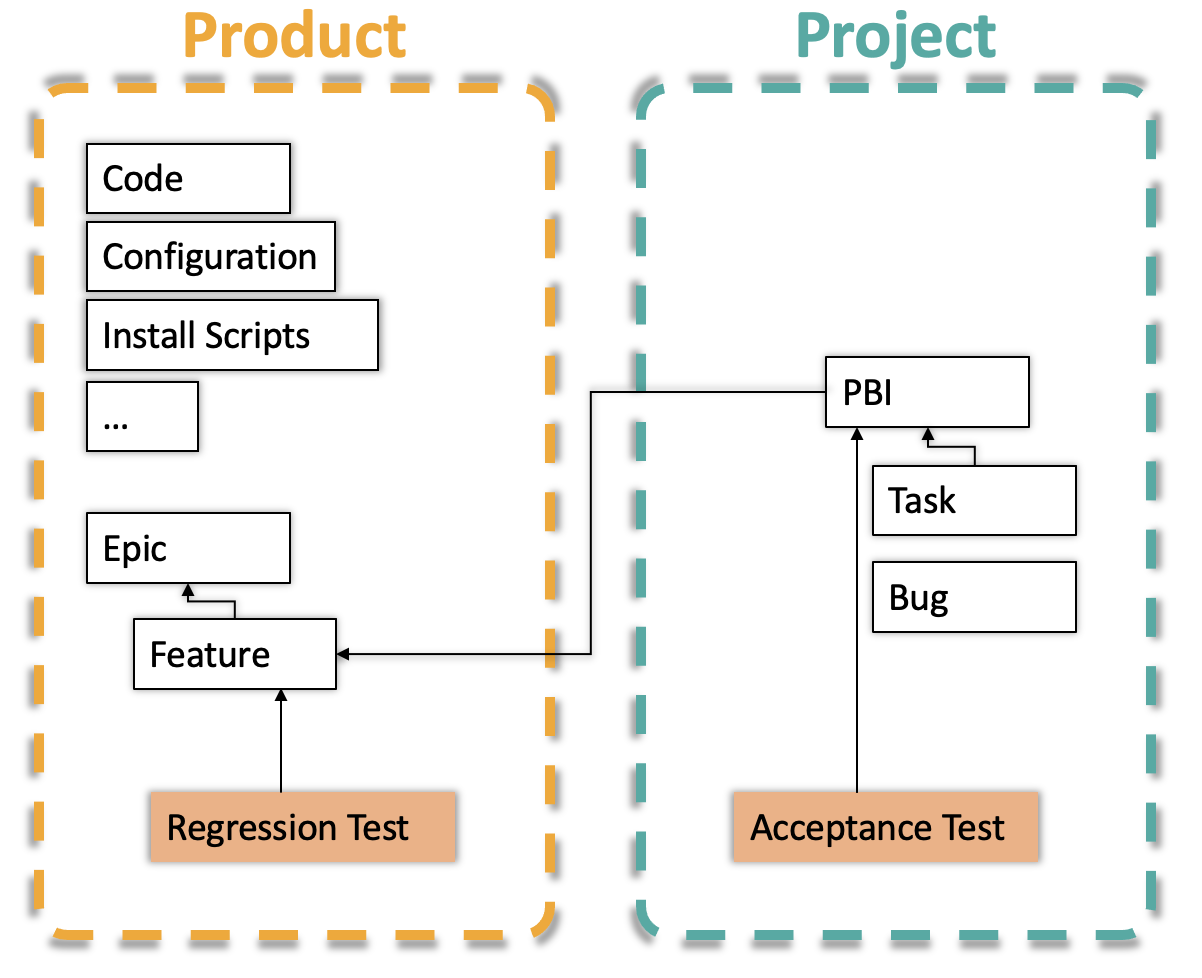
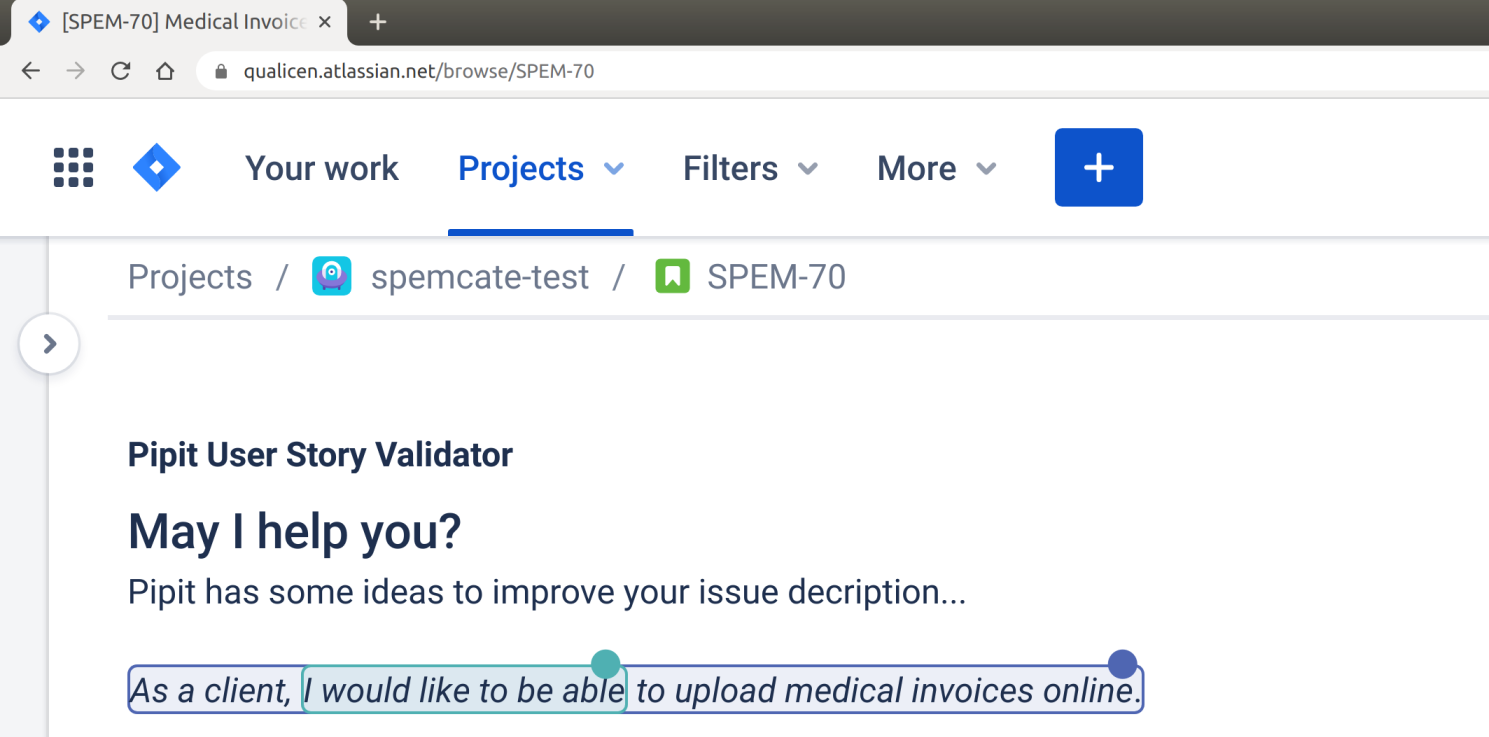
Introducing Pipit – The User Story Validator for Jira
By admin
/ 01/09/2020
User stories and acceptance criterias are the backbone of agile development. Everyone knows badly written user stories provide little value....
Read More
How-to Requirement Reviews
By Arjen Spaans
/ 23/06/2020
Reviews! Either the safety net you always wanted or the hammer that knocks your teeth out. In this blog post...
Read More

Improving the German Corona Warn App Specification
By Maximilian Junker
/ 22/06/2020
Last tuesday, the german Corona Warn App officially launched, following intense and heated discussions about the data protection standards such...
Read More

Test Engineering
Qualicen Snapshot – Ausgabe 2/2021 [in German]
By Silke Müller
/ 09/12/2021
Liebe Freunde und Freundinnen, liebe Partner*innen von Qualicen, das Jahr 2021 neigt sich langsam dem Ende. Hier kommt nun noch rechtzeitig...
Read More
Agile yet Safe! – System Testing in Agile Projects (in JIRA or Azure DevOps)
By Henning Femmer
/ 01/09/2021
Testing plays a central role in agile software development. We usually have unit testing and test automation under control. System...
Read More
Qualicen Snapshot – Edition 1/2021 [in German]
By Silke Müller
/ 31/05/2021
Liebe Freunde und Freundinnen, liebe Partner*innen von Qualicen, es ist soweit: die zweite Ausgabe unseres Snapshots - die erste im Jahr...
Read More
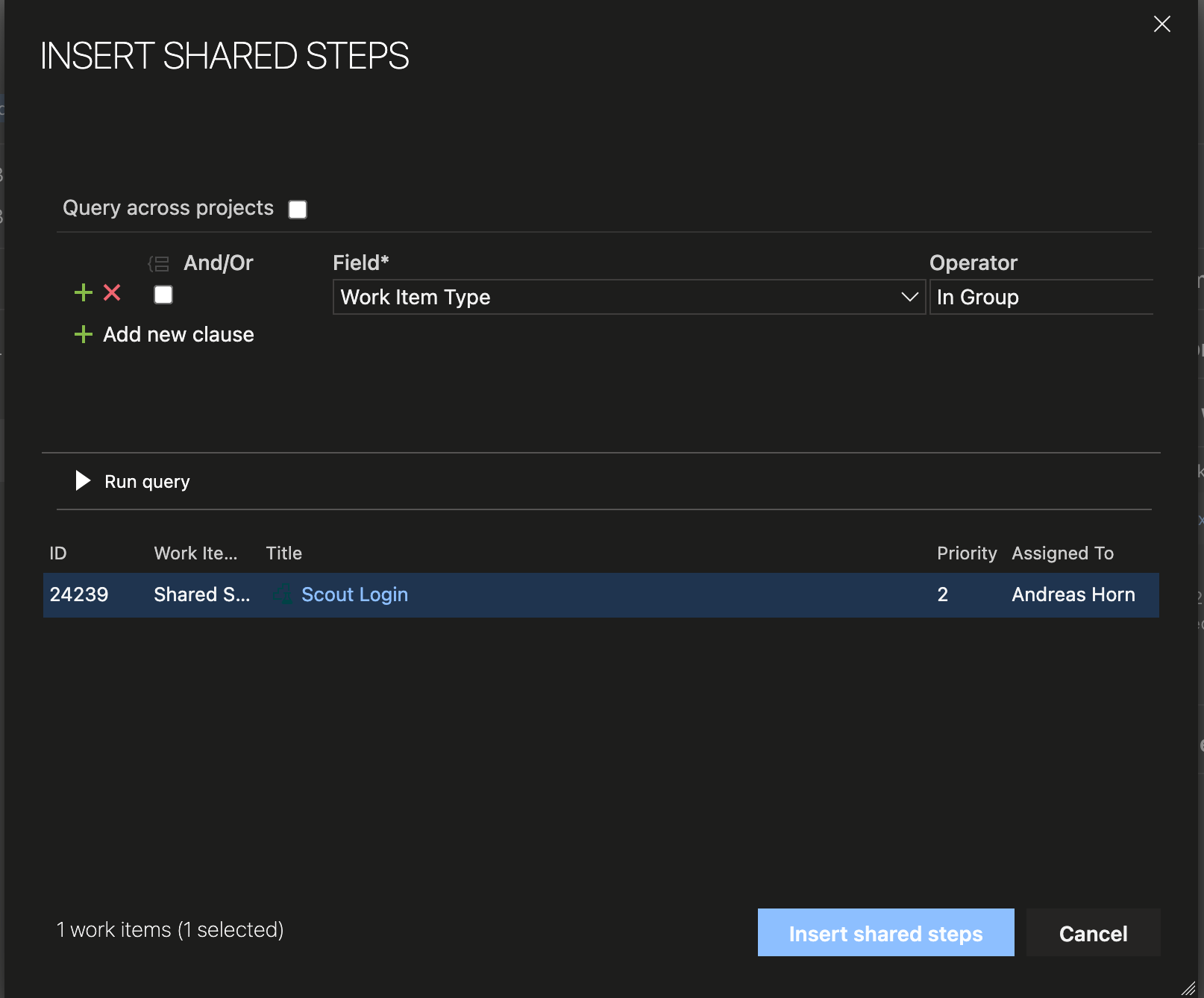
How to Reuse Test Steps and Test Cases in Azure DevOps
By Andreas Horn
/ 30/03/2021
Do you know how many times you changed a test case in Azure DevOps and did not know that there...
Read More
Presenting to You: Qualicen Snapshot [in German]
By Henning Femmer
/ 17/12/2020
Liebe Freund*innen und Partner*nnen von Qualicen, Langsam schaffen wir es nicht mehr uns mit allen Kontakten regelmäßig persönlich auszutauschen. Und manche/r...
Read More
Lessons Learned in monitoring and improving large scale Test Suits
By Andreas Horn
/ 04/06/2020
We run our automated Test Smell Analyses close to 5 years now. Five years in many different projects and domains....
Read More
OTTERs and the Theory of Automatic Testgeneration
By Dominik Spies
/ 10/03/2020
Creating test cases by hand can be a lot of effort. It takes time, and so costs plenty of money....
Read More

Light-weight Requirements Modelling and Test Case Generation: Try it yourself!
By admin
/ 30/10/2018
Automatically generating test cases from requirements? We show you how. For this, we created a new way to create lightweight...
Read More
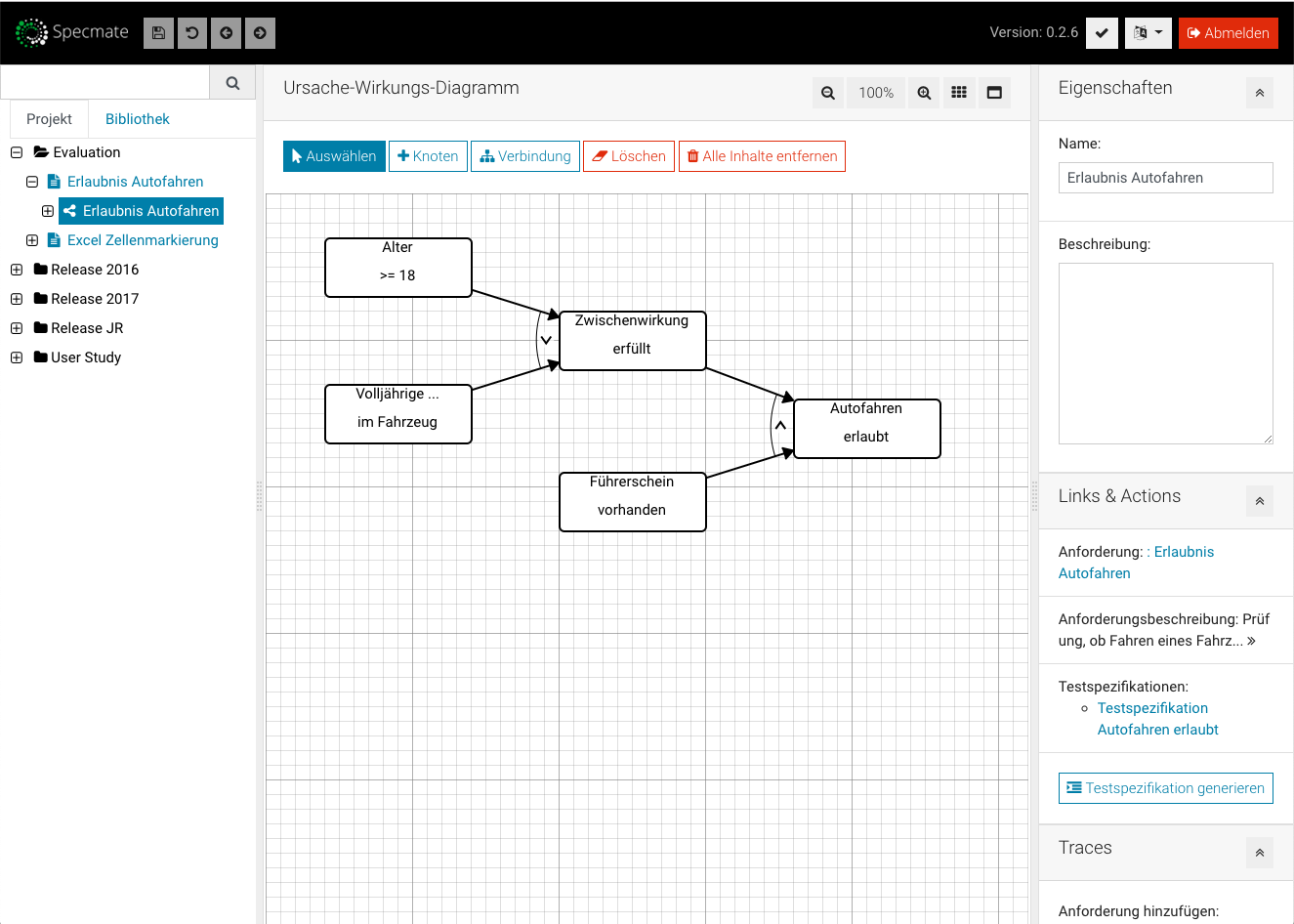
Structured Test-Design with Specmate – Part 1: Requirements-based Testing
By Maximilian Junker
/ 28/02/2018
In this blog post I am going to introduce Specmate, the result of a research project I have been involved...
Read More
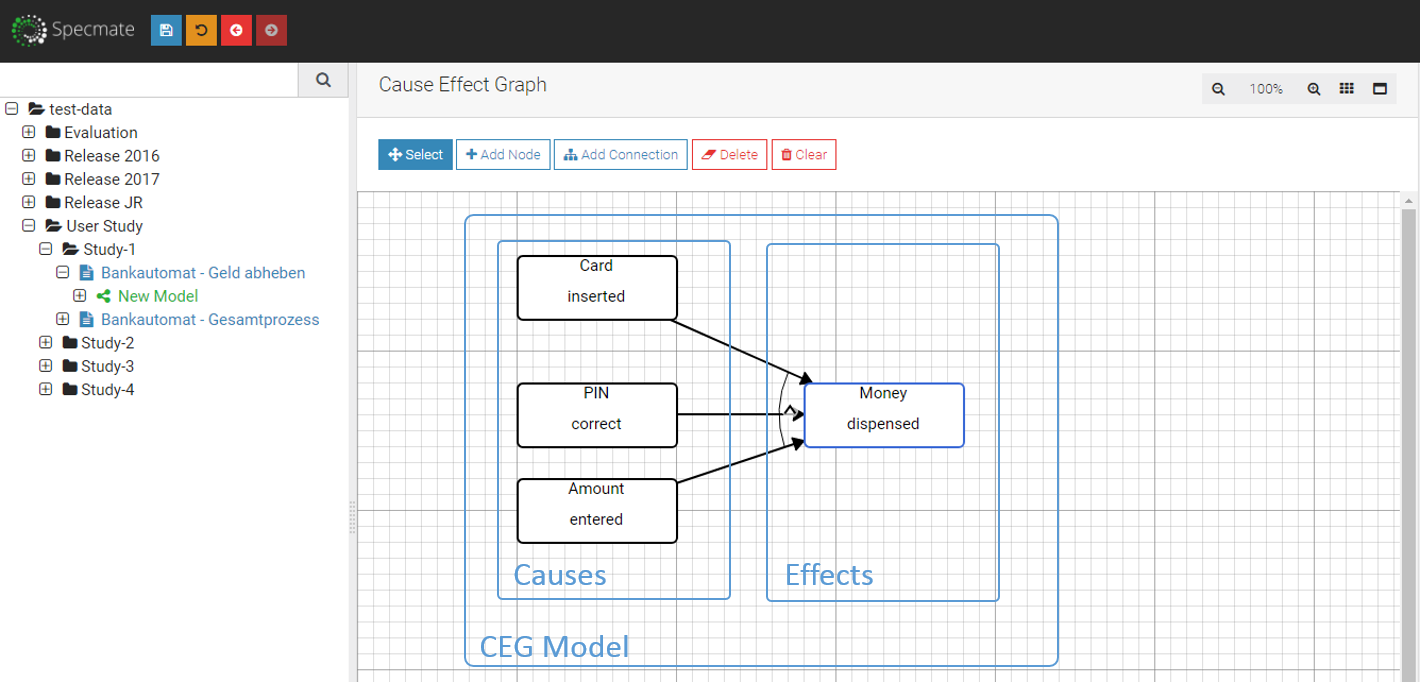
Systems Engineering
Qualicen Snapshot – Ausgabe 2/2021 [in German]
By Silke Müller
/ 09/12/2021
Liebe Freunde und Freundinnen, liebe Partner*innen von Qualicen, das Jahr 2021 neigt sich langsam dem Ende. Hier kommt nun noch rechtzeitig...
Read More
Welcome, Michael Jastram!
By Henning Femmer
/ 18/11/2021
Qualicen is never finished und in kontinuierlicher Veränderung. Dazu gehört auch, dass wir immer wieder neue Mitglieder an Board begrüßen...
Read More

Agile yet Safe! – System Testing in Agile Projects (in JIRA or Azure DevOps)
By Henning Femmer
/ 01/09/2021
Testing plays a central role in agile software development. We usually have unit testing and test automation under control. System...
Read More
MethOps, marrying Methodology and IT-Operations.
By Arjen Spaans
/ 07/06/2021
Dear friends and family, we are gathered today to witness and celebrate the union of MBSE-Methodology and IT-Operations in marriage....
Read More

Qualicen Snapshot – Edition 1/2021 [in German]
By Silke Müller
/ 31/05/2021
Liebe Freunde und Freundinnen, liebe Partner*innen von Qualicen, es ist soweit: die zweite Ausgabe unseres Snapshots - die erste im Jahr...
Read More
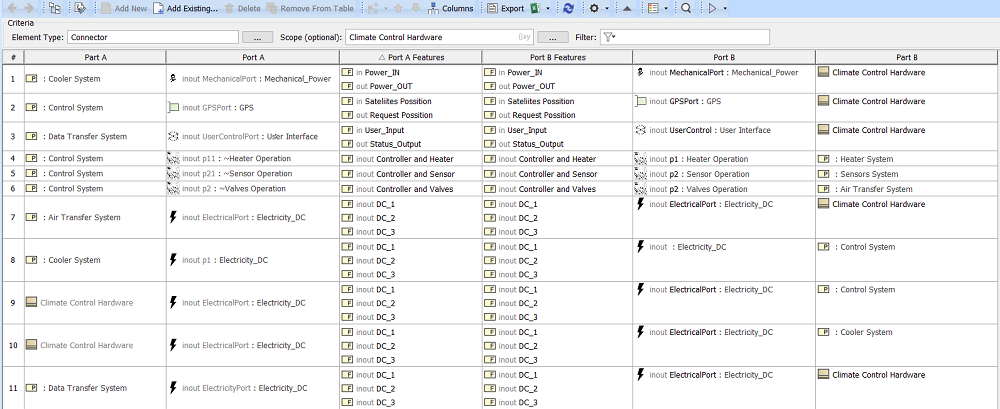
Real Magic: Building Custom Interface Tables with Cameo/Magic Draw and Generic Tables
By Maximilian Junker
/ 08/01/2021
One of the great things about Model-Based Systems Engineering (MBSE) is that the system model enables us to run all...
Read More
Presenting to You: Qualicen Snapshot [in German]
By Henning Femmer
/ 17/12/2020
Liebe Freund*innen und Partner*nnen von Qualicen, Langsam schaffen wir es nicht mehr uns mit allen Kontakten regelmäßig persönlich auszutauschen. Und manche/r...
Read More
Introducing Model-based Systems-Engineering
By Maximilian Junker
/ 01/07/2020
Managing the complexity of cyber-physical systems is a real challenge. Adding reuse and hundreds of product variants doesn't help either....
Read More

Anomaly-Detection with Transformers Machine Learning Architecture
By Maximilian Junker
/ 18/05/2020
Anomaly Detection Anomaly Detection refers to the problem of finding anomalies in (usually) large datasets. Often, we are dealing with...
Read More
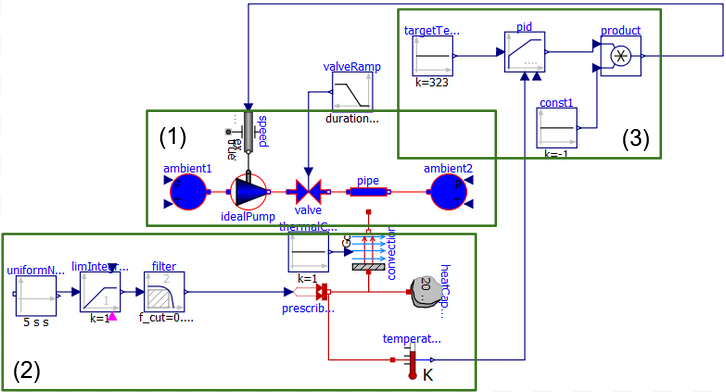
Text Analytics
Qualicen Snapshot – Ausgabe 2/2021 [in German]
By Silke Müller
/ 09/12/2021
Liebe Freunde und Freundinnen, liebe Partner*innen von Qualicen, das Jahr 2021 neigt sich langsam dem Ende. Hier kommt nun noch rechtzeitig...
Read More
Welcome, Michael Jastram!
By Henning Femmer
/ 18/11/2021
Qualicen is never finished und in kontinuierlicher Veränderung. Dazu gehört auch, dass wir immer wieder neue Mitglieder an Board begrüßen...
Read More
Into NLP 6 ~ New Link Project – Dependency Parser
By Dominik Spies
/ 26/07/2021
Today we will talk about one of my favorite tools from the toolbox of classical NLP: The Dependency Parse. Dependencies...
Read More

Into NLP 5 ~ Numerous Language Parts – POS Tagging
By Dominik Spies
/ 31/05/2021
Last time we had a look at the task of text normalization as a way of simplifying matching and searching...
Read More

Qualicen Snapshot – Edition 1/2021 [in German]
By Silke Müller
/ 31/05/2021
Liebe Freunde und Freundinnen, liebe Partner*innen von Qualicen, es ist soweit: die zweite Ausgabe unseres Snapshots - die erste im Jahr...
Read More
Into NLP 4 ~ Normal Language Perfection – Text Normalization
By Dominik Spies
/ 26/04/2021
In my last article I talked about the benefits of tokenization regarding text processing: Essentially when we want to make...
Read More

Into NLP 2 – Fuzzy String Matching and the Edit Distance
By Dominik Spies
/ 01/03/2021
NearLy Perfect In my last article I started with a dive into the wonderfull world of Regular Expressions. We’ve seen...
Read More

Into NLP 1 – Regular Expressions
By Dominik Spies
/ 29/01/2021
Into the Fire - A no less somewhat less nonsense introduction to NLP Natural Language Processing? - What is NLP?...
Read More

Presenting to You: Qualicen Snapshot [in German]
By Henning Femmer
/ 17/12/2020
Liebe Freund*innen und Partner*nnen von Qualicen, Langsam schaffen wir es nicht mehr uns mit allen Kontakten regelmäßig persönlich auszutauschen. Und manche/r...
Read More
Talks / News
Qualicen Snapshot – Ausgabe 2/2021 [in German]
By Silke Müller
/ 09/12/2021
Liebe Freunde und Freundinnen, liebe Partner*innen von Qualicen, das Jahr 2021 neigt sich langsam dem Ende. Hier kommt nun noch rechtzeitig...
Read More
Goodbye Garching! Hello Munich!
By Silke Müller
/ 25/11/2021
Start spreading the news, we´re leaving today, we want to be a part of it…Munich, Munich. 😉 Oh no, let´s...
Read More

Qualicen Snapshot – Edition 1/2021 [in German]
By Silke Müller
/ 31/05/2021
Liebe Freunde und Freundinnen, liebe Partner*innen von Qualicen, es ist soweit: die zweite Ausgabe unseres Snapshots - die erste im Jahr...
Read More
Presenting to You: Qualicen Snapshot [in German]
By Henning Femmer
/ 17/12/2020
Liebe Freund*innen und Partner*nnen von Qualicen, Langsam schaffen wir es nicht mehr uns mit allen Kontakten regelmäßig persönlich auszutauschen. Und manche/r...
Read More
Happy Birthday, Qualicen!
By Silke Müller
/ 26/11/2020
Five years? Really? Time must have been flying! Did you know the idea of founding Qualicen originated at Technical University...
Read More

Research in times of Corona
By Jannik Fischbach
/ 04/11/2020
Corona influences pretty much all areas of our lives by now - both privately and professionally. This year, Corona also...
Read More

Conference Report: QS-Tag Frankfurt
By admin
/ 07/11/2019
Last week, we were at QS-Tag in Frankfurt, Germany. QS-Tag is a great venue for testers and everyone else who...
Read More

Conference Report: RE Conference (JeJu Island, South Korea)
By Jannik Fischbach
/ 01/10/2019
Since this is my first blog article, I would like to take the opportunity to introduce myself. My name is...
Read More

Hear us speak at REConf 2018
By Henning Femmer
/ 02/03/2018
Falls Ihr/Sie nächste Woche in München seid, kann man fast gar nicht über die REConf 2018 laufen ohne uns zu begegnen: Keynote:...
Read More
