Agile yet Safe! – System Testing in Agile Projects (in JIRA or Azure DevOps)
Testing plays a central role in agile software development. We usually have unit testing and test automation under control. System testing, and in particular regression testing is often methodologically more difficult. Recently more and more test manager approach me and ask: “Based on what do I generate my tests in agile? Which tests do I have to maintain and which do I execute?”
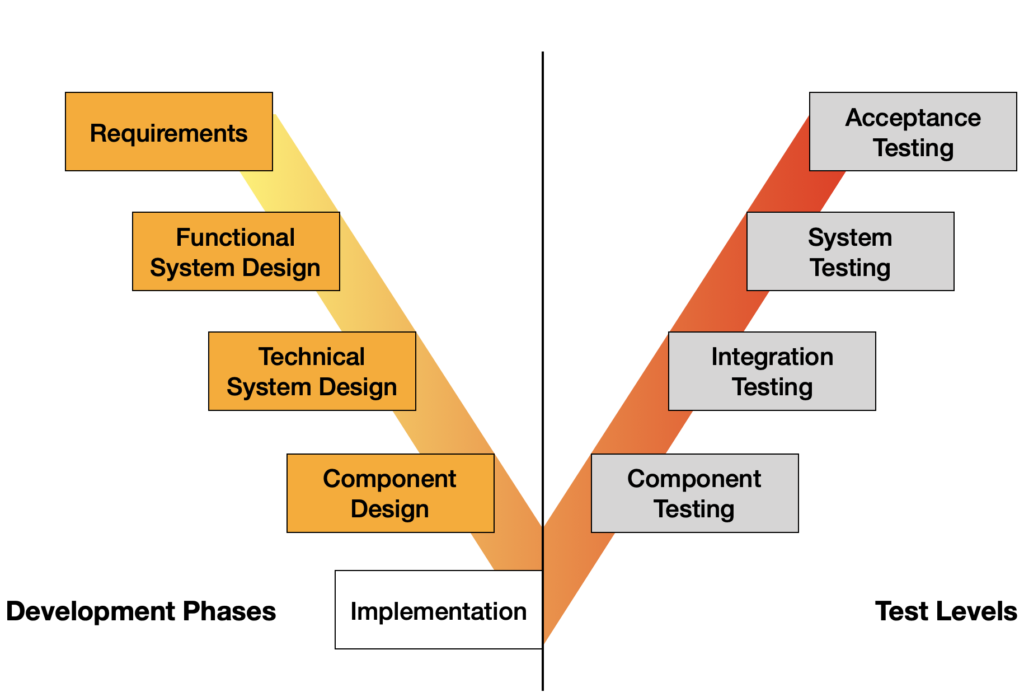
Based on: Spillner; Linz. Basiswissen Softwaretest. dpunkt. verlag, 2019.
My first response is usually to grab my Spillner Book or my ISTQB syllabus and say: “Well, it’s rather simple: Let’s check your prioritized and structured requirements, and we should be ready to go!” to which customers usually respond “Henning, requirements? We’re agile!”. The fundamental problem is: In agile software development, there is usually no requirement specification as a source for regression tests. Work items, such as user stories, are not suitable for this because they do not represent the status quo of the system but only deltas and are not updated.
In this blogpost I want to show three possible approaches to escape this chaos, each with upsides and downsides.
Three reasons why User Stories suck as a basis for regression tests.
Many people use user stories in agile projects as a replacement for requirements specifications. As such, some argue that we can use the user stories – and especially their acceptance criteria – as a basis for system tests. While this works for test case creation, it sucks for maintaining regression test. Which is a huge problem, because that’s what any non-trivial project is mainly about after a while. Here a why it sucks:
- User stories (often written in the pattern “As a … I want … so that…“) describe a small unit of functionality that needs to be done next. They are not intended to describe complete intended system behavior. User stories are created for a specific moment of the project, i.e. within one specific time context. After a while that context is lost. As a consequence, it becomes impossible to understand user stories after a while. To give an example, let’s assume that a user story says: “As an insurance broker, I want to calculate premiums, so that I can offer my clients a concrete offer.” In this case, premiums at an early point of the project might refer to, for example, premiums for auto insurance, since this was what the company originally focused on. But let’s say that the company grew, and now the company offers a wide range of premiums. Imagine now that a new developer joins the team. Now what does the original user story refer to? Albeit perfectly clear in the original context, the story is now unclear in the new context.
- User stories are primarily work items for task management. This means that I’ve yet to see a team to update a user story after it is completed. So, if you look at a user story after it is finished you do not know whether it is still valid.
- Regular projects have A LOT OF user stories. For example, a small web shop team, I worked with had about a thousand user stories in two years.
And this is the simple reason why so many people struggle during system testing for agile projects.
That sucks, right? So, what do we do?!
We need a backbone for tests!
What we need is a (functional) system structure, which provides us with what I call the backbone of the system. But what does it look like? Depending on your style, we have seen three general models of backbones:
- Heavy-weight Requirements Specifications or User Specifications or Documents
- Light-weight Functional Structures
- Model-based Requirements and Model-based Testing
Let’s look at them a little closer and discuss their advantages and disadvantages!
Option 1: Heavy-weight Requirements Specifications or User Specifications or Documents
So, let’s start with something simple. So if we need requirements or specifications for system testing, let’s just add them to our work products. At the end, the agile manifesto says “working software over comprehensive documentation” and not “working software instead of documentation.”, right? So, what we only have to do is to create a thorough specification, for example as use cases.

What’s different to plain old waterfall requirements engineering? Well, instead of eliciting the full-blown requirements up front, you add them just-in-time as Scott Ambler describes it in his classic Agile Modeling. So, specifying the details either becomes part of the definition-of-ready (DoR) or of the definition-of-done (DoD), depending how you like it.
Again referring to Ambler, we also have to make sure that the documentation is not a refrigerator, where the requirements rot, but instead a place where the requirements can circulate and are touched by many hands and seen by many eyes. Tools like Atlassian Confluence or other wikis are great examples for this.
And that’s it, now you can link your regression test cases against your requirements and you now: Whenever we change something in the requirements, we have to check, which test cases are testing these requirements? Those are your primary test cases for regression tests! And at the same time, you will much more quickly identify side effects of your changes.
| Advantages | Disadvantages |
|---|---|
| There is one place to go to understand your system behavior. It’s a good starting point for new employees to get started with your system. Very easy to introduce, very few process changes. | You’re back in the old requirements engineering game: Risk of overheads… |
Option 2: Light-weight Functional Structures
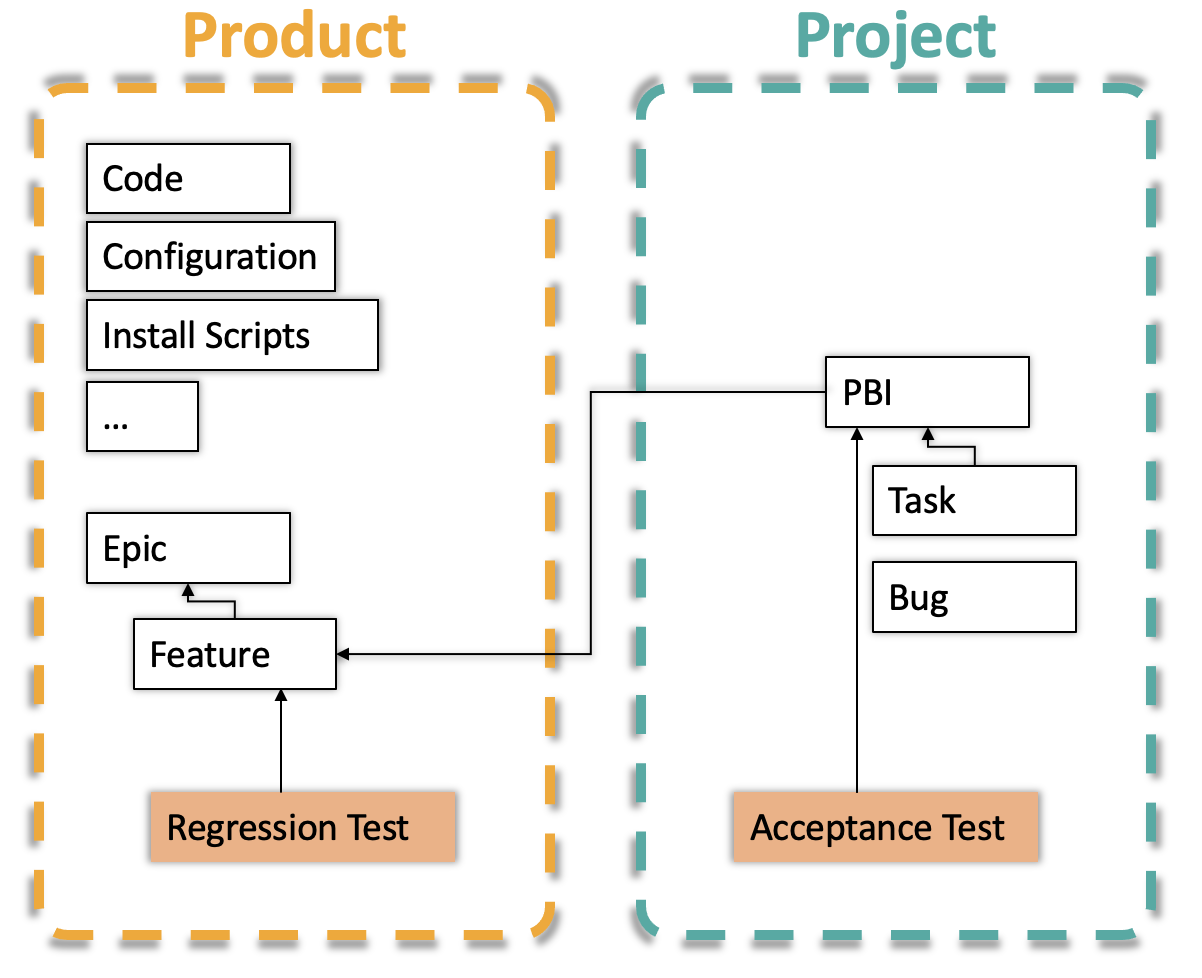
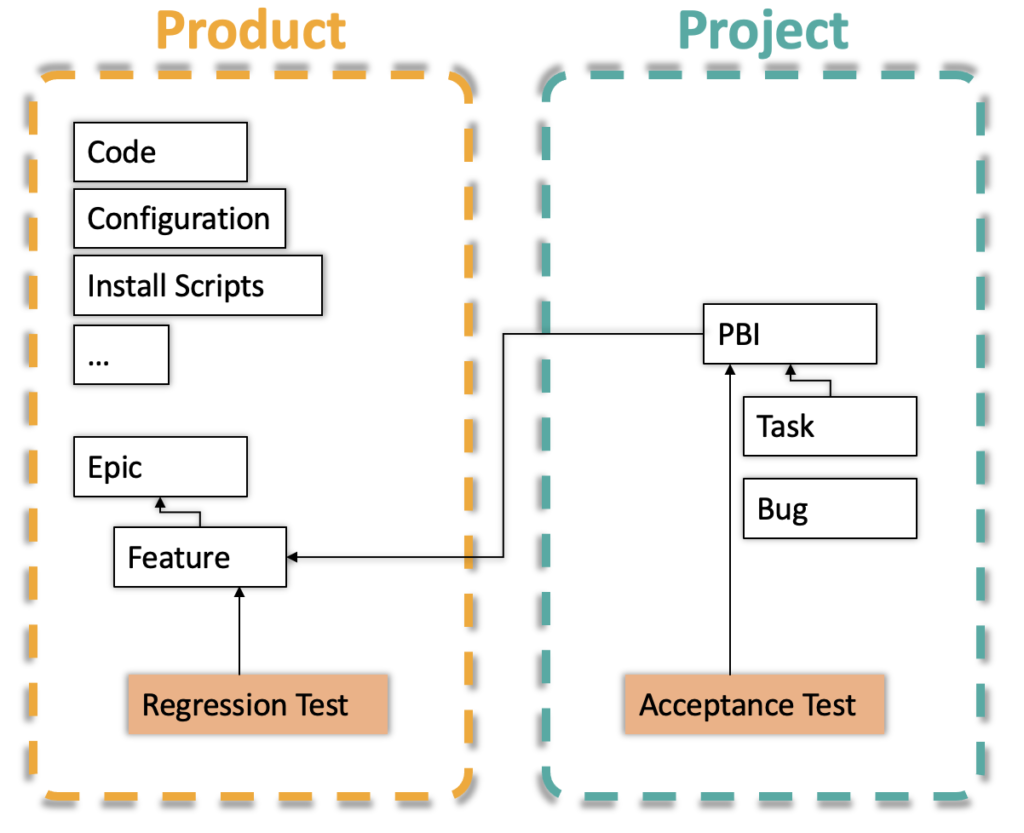
The second option is a little more light-weight. This is particularly interesting if you don’t want to specify the whole system, but only parts. What you need now, is just a skeleton of your requirements specification. Precisely, what you need is a rough model of the functional structure of your product. Typical examples can again be the use cases of your system, but other options are main features. These can then be broken down into subfeatures etc.
The test cases of the project can then be linked against the features of the product (see image underneath). So whenever a new PBI (product backlog item, such as user story), is implemented, we immediately now, that we need to re-run the other test cases linked to this feature. Keep in mind that a regression test can test multiple features. This is also no problem for our product structure here.
| Advantages | Disadvantages |
|---|---|
| Simple to set up, low overhead. Integrates nicely into development environment. Can easily be adjourned by detailed requirements for the high-risk features if needed. | Function cut can be difficult, might need some thinking to be neither to rough nor get lost in details. |
Option 3: Model-based Requirements and Model-based Testing
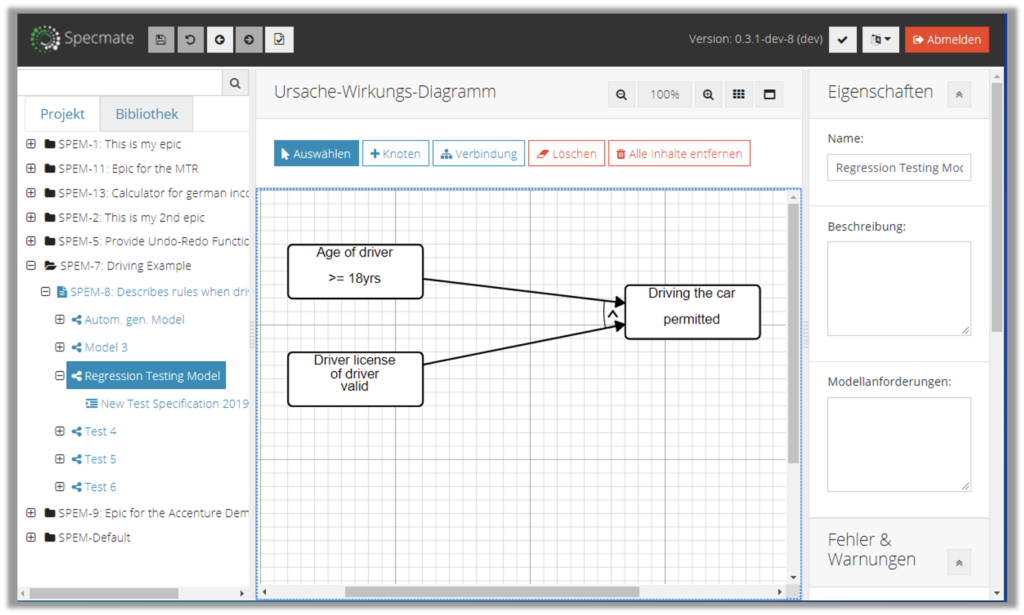
Finally, the methodically cleanest but also most challenging approach is to rip up that artificial border between requirements and test. Instead, you can describe your requirements in a way that will allow you to derive your test cases automatically. Mostly, you will describe your requirements as cause-effect-chains or as activity flows. Those two types implicitly also contain their test cases. All that we need to do is model them in a precise language, such as Specmate (check these posts for more details) and Specmate generates the test cases for you.
This is the core idea of model based testing and was always one application of model based requirements engineering. When they come together, the whole issue of traceability, maintaining test cases etc. becomes less relevant.
| Advantages | Disadvantages |
|---|---|
| Simpler testing. Cheaper maintenance of test cases. | Large methodical step, more difficult to introduce. New tools need to be integrated with the tool landscape. |
TLDR;
You need more than user stories if you want to do proper system and regression testing in your project. There are three options for such a backbone: Either with classic documents for example in Atlassian Confluence, or with a functional structure in your JIRA, or with model-based requirements which allow you to generate the test cases directly.
What is the right way for you? Well, it absolutely depends on your teams methodological skills, on their openness for tools. It depends on how agile your folks are. But ultimately, you will need to find it out yourself. If you need help on the way, contact me by mail or via linkedin.



