
Check Your Requirements Quality with One Click – Everywhere!
Checking the quality of requirements is not just useful. Considering the complexity of modern product development, bad requirements can easily derail a project. We at Qualicen have been helping our customers now for over five years: both with our expertise

Qualicen Snapshot – Ausgabe 2/2021 [in German]
Liebe Freunde und Freundinnen, liebe Partner*innen von Qualicen, das Jahr 2021 neigt sich langsam dem Ende. Hier kommt nun noch rechtzeitig vor den Feiertagen unser neuer Snapshot. Mit diesem Format sind wir im Dezember 2020 gestartet und wollen Sie zweimal im Jahr
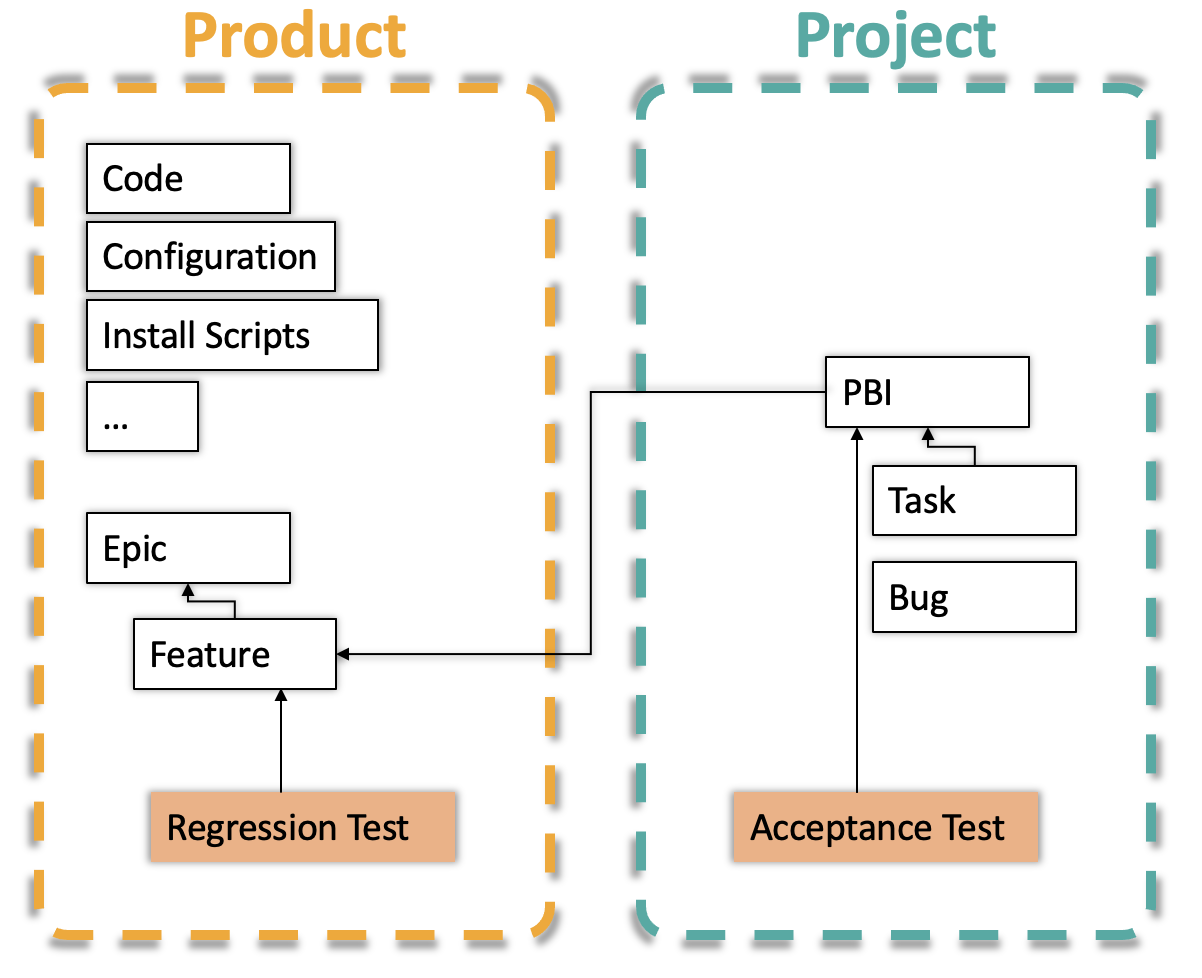
Agile yet Safe! – System Testing in Agile Projects (in JIRA or Azure DevOps)
Testing plays a central role in agile software development. We usually have unit testing and test automation under control. System testing, and in particular regression testing is often methodologically more difficult. Recently more and more test manager approach me and

Qualicen Snapshot – Edition 1/2021 [in German]
Liebe Freunde und Freundinnen, liebe Partner*innen von Qualicen, es ist soweit: die zweite Ausgabe unseres Snapshots - die erste im Jahr 2021 - ist fertig. Wir sind im Dezember 2020 mit diesem neuen Format gestartet und möchten uns zuerst noch einmal ganz
Mature Enough? Using Maturity Models to Assess and Improve Software Projects
It is not rare that projects approach us not as a consultant firm but more like a medical first-aid station. In those cases, the patient represents a software or engineering project that is hanging on by a bare thread. So

Presenting to You: Qualicen Snapshot [in German]
Liebe Freund*innen und Partner*nnen von Qualicen, Langsam schaffen wir es nicht mehr uns mit allen Kontakten regelmäßig persönlich auszutauschen. Und manche/r scheut vielleicht die Hürde uns einfach mal auf die neuesten Entwicklungen anzusprechen. Und auch nicht jede/r hat die Zeit unseren Updates
Hey BERT, do you recognize any requirements?
Does scanning for your relevant requirements in massive documents sound familiar? In this blog post we are going to find them for you
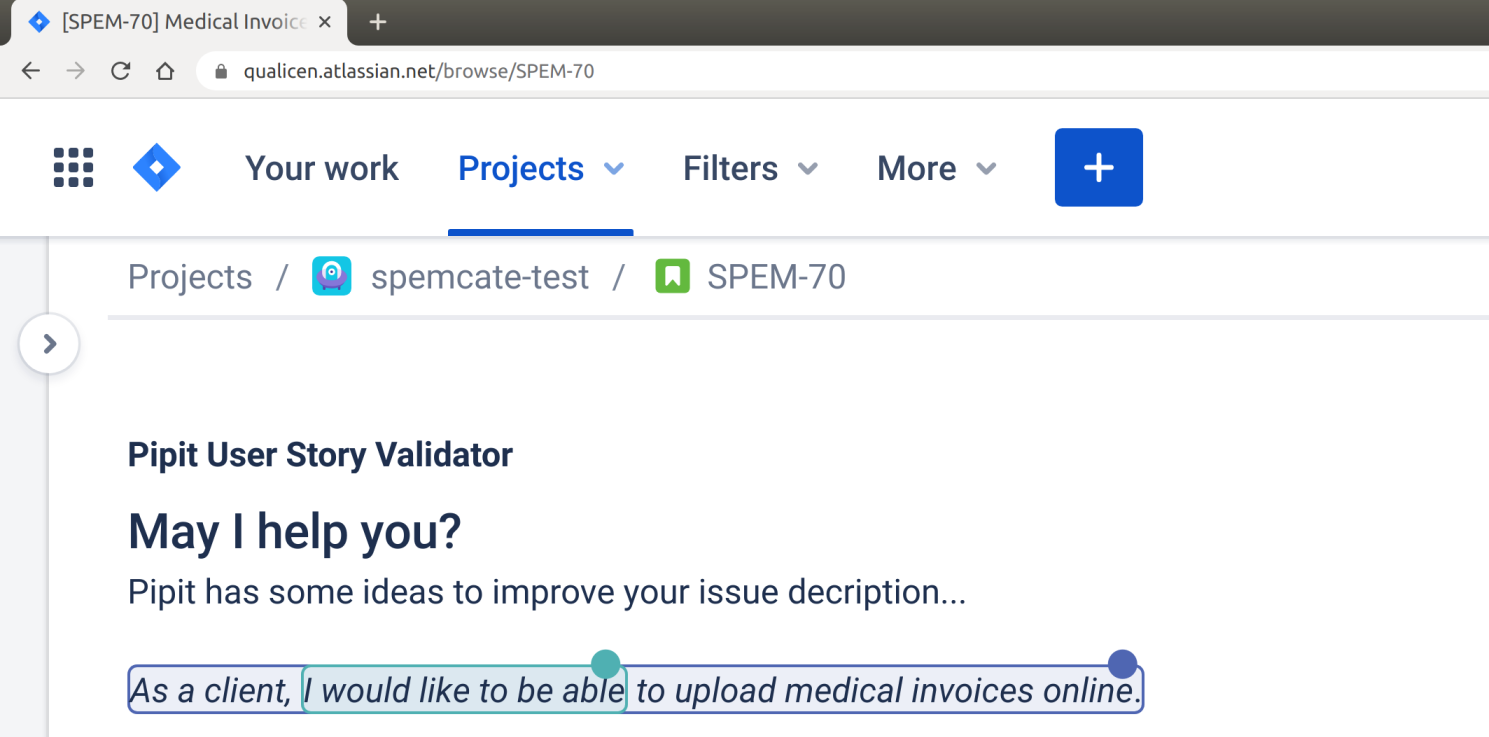
Introducing Pipit – The User Story Validator for Jira
User stories and acceptance criterias are the backbone of agile development. Everyone knows badly written user stories provide little value. In extreme cases, they even do more harm than good. Therefore, many best practices and templates exist guiding us to

How-to Requirement Reviews
Reviews! Either the safety net you always wanted or the hammer that knocks your teeth out. In this blog post we will explain how to conduct a valuable, effective and pleasant requirement review.

Improving the German Corona Warn App Specification
Last tuesday, the german Corona Warn App officially launched, following intense and heated discussions about the data protection standards such an app should adhere to. In order to achieve transparency about the inner workings of the app, including which data