Mature Enough? Using Maturity Models to Assess and Improve Software Projects
It is not rare that projects approach us not as a consultant firm but more like a medical first-aid station. In those cases, the patient represents a software or engineering project that is hanging on by a bare thread. So
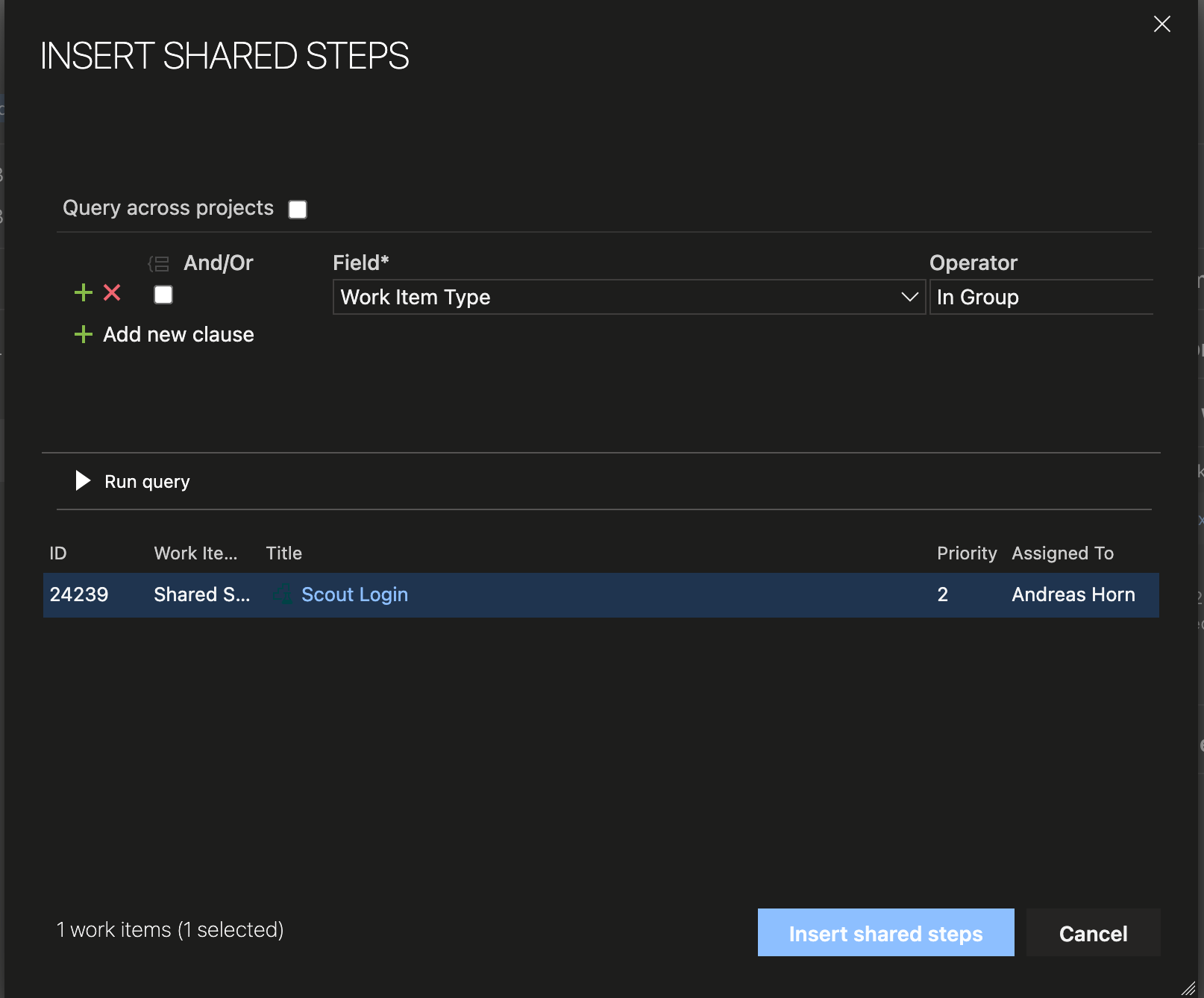
How to Reuse Test Steps and Test Cases in Azure DevOps
Do you know how many times you changed a test case in Azure DevOps and did not know that there were 2 other test cases with the same steps (so called “clones”), that you should have changed, too? Do you
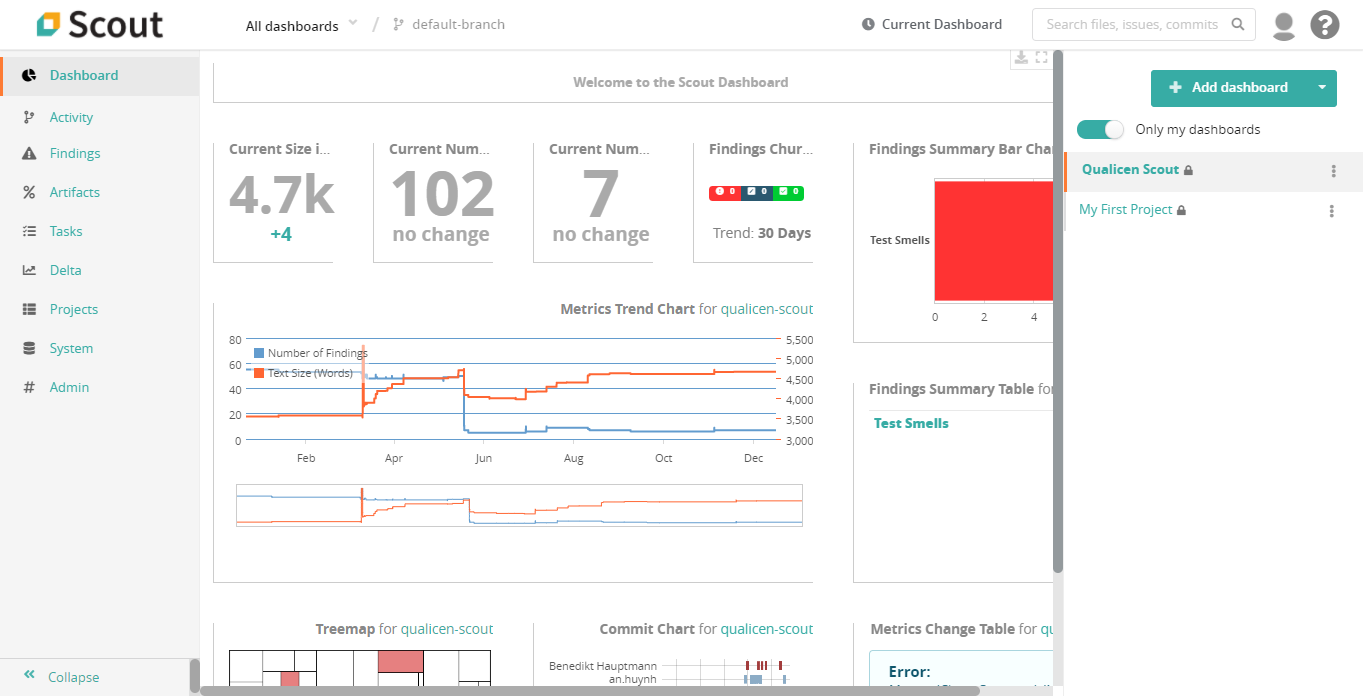
Release: Qualicen Scout 5.4-1
We are proud to announce the latest release of our automated quality analysis tool: Scout 5.4-1. In this release we incorporated many new features, and improved existing ones. In this blogpost we provide a brief overview of the most

The Incredible Potential of Text Analytics – The Use Cases Explained.
New advances in text analytics make the tech news nearly every week, most prominently IBM Watson, but also more recently AI approaches such as ELMo or BERT. And now it made world news with the pandemic caused by the Covid-19 virus, with the white house requesting help via NLP.
Text Analytics and Natural Language Processing (NLP) deal with all types of automatic processing of texts and is often built on top of machine learning or artificial intelligence approaches. The idea of this article is not to explain how text analytics works, but instead to explain what is possible.

OTTERs and the Theory of Automatic Testgeneration
Creating test cases by hand can be a lot of effort. It takes time, and so costs plenty of money. It is estimated that testing on average costs roughly 50% of the project budget.So maybe, we could try and skip it? Well, we still need to test and, among other things, make sure that the system behaves in the way we specified. But maybe we can develop an automatic method for creating tests? And this is the core idea: Why not use the specification to generate the tests?

Automatic Feedback on TFS/VSTS Test Case Quality in Real Time
Team Foundation Server (TFS) and its software-as-a-service counterpart Microsoft Visual Studio Team Services (VSTS) are widely used application lifecycle management (ALM) and test management tools. They offer many great facilities to create tests, manage test plans, and execute them. Consequently, many of our clients as well as prospective customers wanted to use our test improvement software Test Scout along with TFS/VSTS to improve the test case quality. So, here is the question that we always face: How do we get the data from a testing tool into the Test Scout? As always in life, there is a straightforward and a fancy solution. Let me show you what I mean.
First: a simple integration
Test Scout is able to process almost any kind of text format. So, integrating test management tools such as TFS/VSTS is quite straightforward: For each test management tool, we created exports, which we imported into the Scout. For HP ALM, for example, we use a simple script to create a database dump containing all currently existing test cases. We then automatically imported and processed this data in Test Scout to evaluate the test case quality. Since Test Scout keeps versions of each import in its database, the history of all test cases is available in Test Scout. Therefore, all features, such as comparing different versions of test cases and historical development of test cases still works out of the box.
Efficiently control requirements quality: the best of two worlds
For high requirements quality we need quality assurance. In a previous post, I explained why automatic methods cannot replace manual methods. Instead I suggested to combine both worlds. And the ugly truth is, in both system testing and requirements engineering, we need both manual and automatic quality assurance to control requirements quality and test quality. Now you wonder, how? I got you covered. In this brief post, I want to point out how you can combine the two worlds and how you benefit from the combination.
The ugly truth about automatic methods for requirements engineering quality.
Ok, after I publish this blog post, I will probably get some angry calls from my sales department... Well, truth must be told. There are many crazy defects in requirements, and, as I wrote in my last post, you can detect quite a bunch of them automatically (and you should do so!). When I present our automatic methods for natural language requirement smells or automatic methods for detecting defects in tests to our customers, I'm proud to say that they are usually very excited. Sometimes they are too excited and then this can turn into a problem. What I mean is that I explain all the amazing things that you can detect with tools and suddenly people think that the tool will solve all the problems that they face. Spoiler alert: It doesn't. And because we're a company that is interested in happy customers, I want to briefly summarize all the problems (*that come into my mind) that a tool can't solve. And because I don't want to leave you in despair, I will also suggest some solutions, how I personally would suggest to work on that problem.
Structuring system test suites – antipatterns and a best practice
Typically, you have your test suite structured in a hierarchic way to keep it organized. The way you structure your system test suite has a considerable impact on how effective and efficient you can use your tests. A good structure of a system test suite supports:
- maintaining tests when requirements change
- determine which part of your functionality has been tested, and to which degree (coverage)
- finding and reusing related tests while creating new tests
- selecting a set of test cases to execute (test plan)
- finding the root cause of a defect (debugging)
Which quality defects can you automatically detect in system tests and requirements?
I am a strong advertiser of modern, automatic methods to improve our day to day life. And so I really don't want to check by hand whether my tests and requirements fit my template, or whether my sentences are readable. So quality assurance and defect detection, for example reviews or inspections, should use automation as far as possible. BUT: When I speak to clients, sometimes people get so hooked up by the idea of automatic smell detection, that I need to slow them down. Therefore, this post tries to give a rough overview: What is possible to detect automatically? The answer basically depends on two questions:
- How much syntax (or structure) do your artifacts and tests have?
- Which language do you use?