
Qualicen Snapshot – Ausgabe 2/2021 [in German]
Liebe Freunde und Freundinnen, liebe Partner*innen von Qualicen, das Jahr 2021 neigt sich langsam dem Ende. Hier kommt nun noch rechtzeitig vor den Feiertagen unser neuer Snapshot. Mit diesem Format sind wir im Dezember 2020 gestartet und wollen Sie zweimal im Jahr
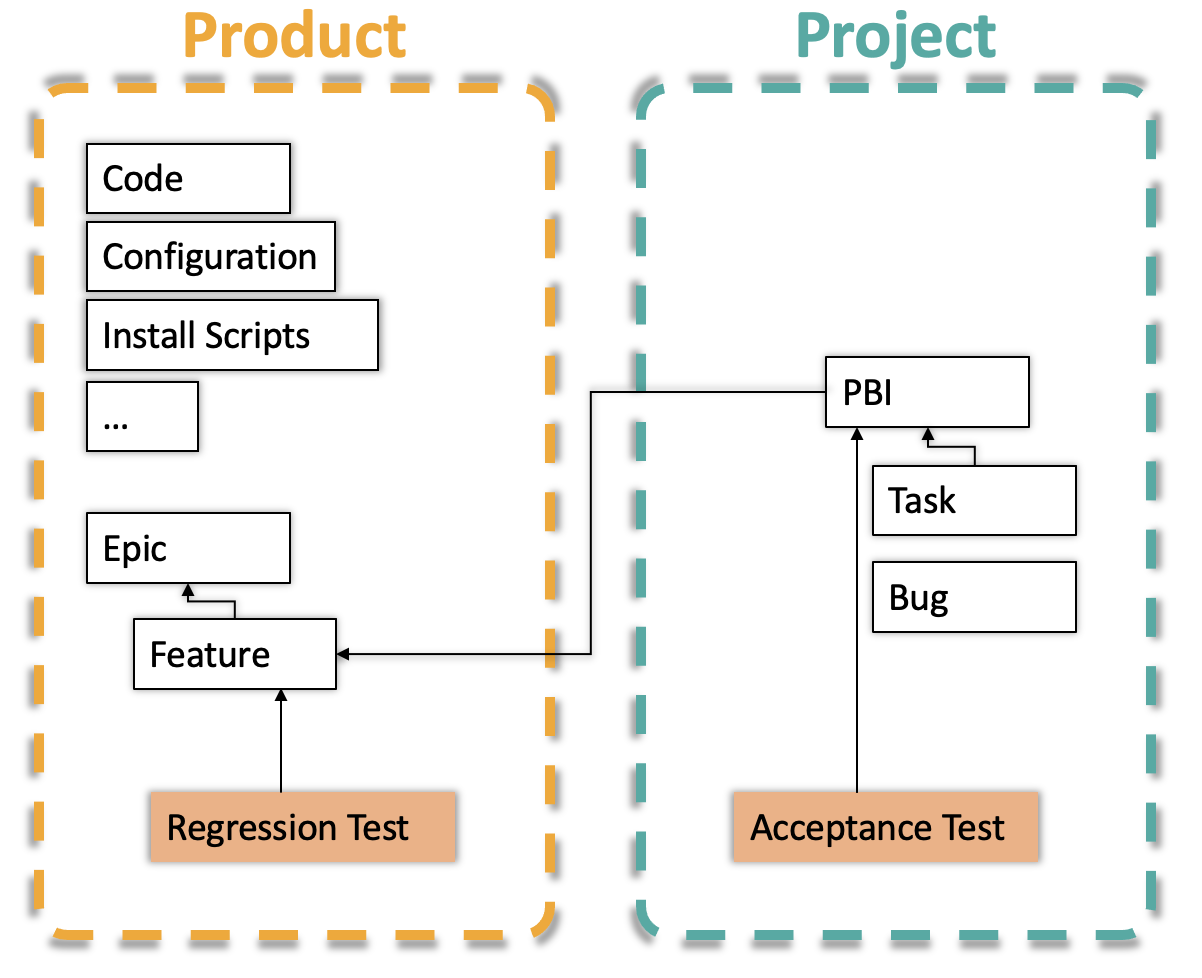
Agile yet Safe! – System Testing in Agile Projects (in JIRA or Azure DevOps)
Testing plays a central role in agile software development. We usually have unit testing and test automation under control. System testing, and in particular regression testing is often methodologically more difficult. Recently more and more test manager approach me and

Qualicen Snapshot – Edition 1/2021 [in German]
Liebe Freunde und Freundinnen, liebe Partner*innen von Qualicen, es ist soweit: die zweite Ausgabe unseres Snapshots - die erste im Jahr 2021 - ist fertig. Wir sind im Dezember 2020 mit diesem neuen Format gestartet und möchten uns zuerst noch einmal ganz
Mature Enough? Using Maturity Models to Assess and Improve Software Projects
It is not rare that projects approach us not as a consultant firm but more like a medical first-aid station. In those cases, the patient represents a software or engineering project that is hanging on by a bare thread. So
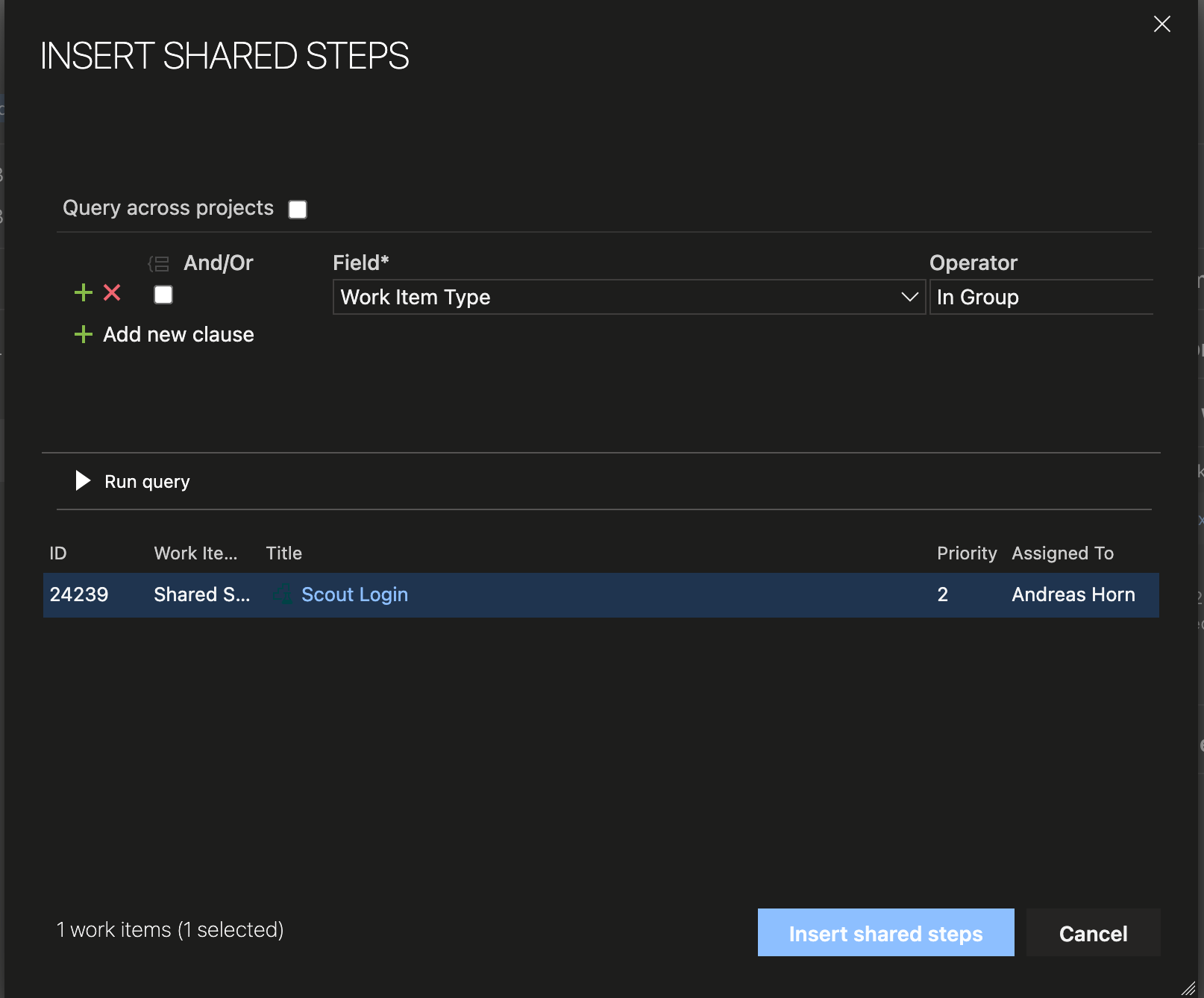
How to Reuse Test Steps and Test Cases in Azure DevOps
Do you know how many times you changed a test case in Azure DevOps and did not know that there were 2 other test cases with the same steps (so called “clones”), that you should have changed, too? Do you

Presenting to You: Qualicen Snapshot [in German]
Liebe Freund*innen und Partner*nnen von Qualicen, Langsam schaffen wir es nicht mehr uns mit allen Kontakten regelmäßig persönlich auszutauschen. Und manche/r scheut vielleicht die Hürde uns einfach mal auf die neuesten Entwicklungen anzusprechen. Und auch nicht jede/r hat die Zeit unseren Updates
Lessons Learned in monitoring and improving large scale Test Suits
We run our automated Test Smell Analyses close to 5 years now. Five years in many different projects and domains. Time to collect lessons learned and provide a historic view regarding the evolution of our automatic test analysis. But let's

OTTERs and the Theory of Automatic Testgeneration
Creating test cases by hand can be a lot of effort. It takes time, and so costs plenty of money. It is estimated that testing on average costs roughly 50% of the project budget.So maybe, we could try and skip it? Well, we still need to test and, among other things, make sure that the system behaves in the way we specified. But maybe we can develop an automatic method for creating tests? And this is the core idea: Why not use the specification to generate the tests?
Light-weight Requirements Modelling and Test Case Generation: Try it yourself!
Automatically generating test cases from requirements?
We show you how. For this, we created a new way to create lightweight models for requirements. The advantage of lightweight models over text: These models can automatically generate test cases. How awesome is that? Check out our youtube demo to see the system in action: [embed]https://www.youtube.com/watch?v=PlaOzUmVIcM[/embed] You can find more information in two blog posts: Part 1 and Part 2. Or, check out our live demo and try it yourself: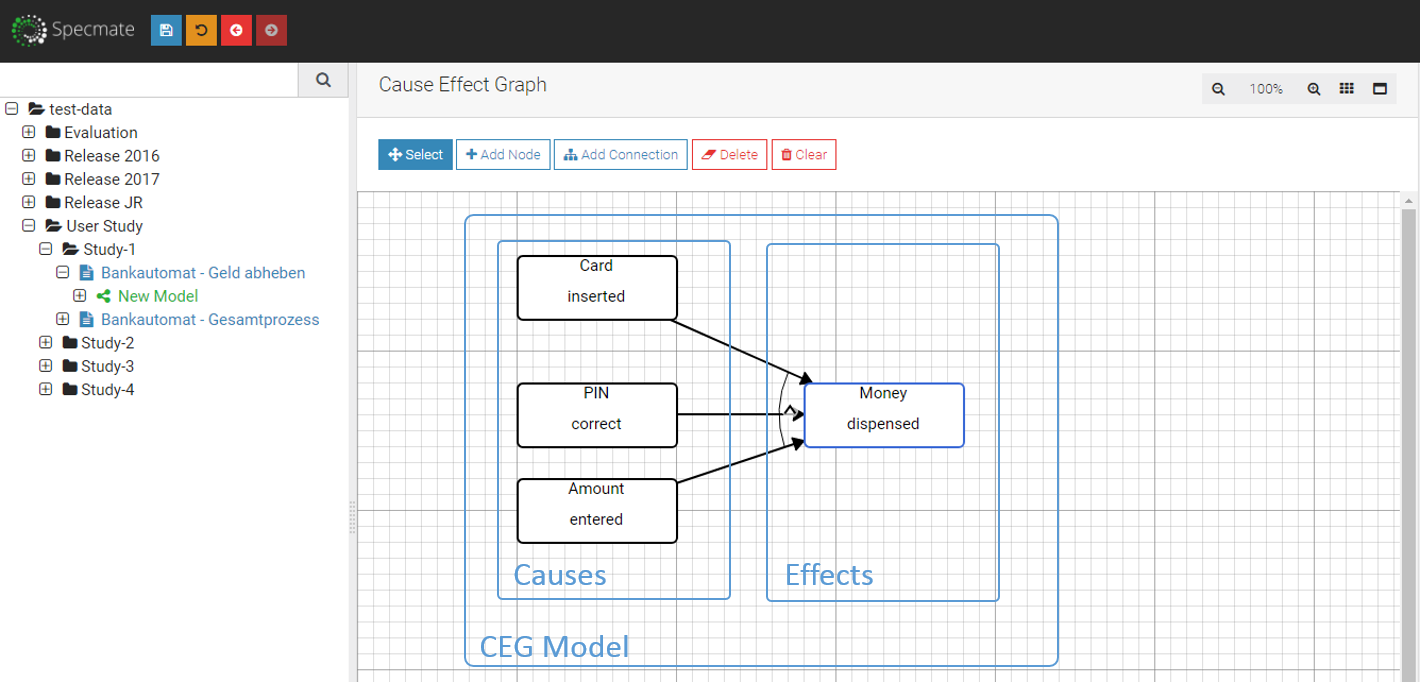
Structured Test-Design with Specmate – Part 1: Requirements-based Testing
In this blog post I am going to introduce Specmate, the result of a research project I have been involved into. It is an open-source tool to automate test-design, among others. This is the first post of a series in which I am going to show you some of the ideas behind Specmate.
What is test-design and why does it matter?
Test-Design is the activity to come up with the right test-cases for a piece of functionality. But what are the right test-cases? There are many criteria, depending on your focus. For me, there are two main points:- First, they should test the right content. That means, they relate to the requirements for this functionality and cover every aspect that the requirements talk about. They should hence be able to find faults: deviations of the implementation with respect to the specification.
- Second, they should be feasible. That means, it should be possible to execute the test-cases without wasting resources.