Check Your Requirements Quality with One Click – Everywhere!
Checking the quality of requirements is not just useful. Considering the complexity of modern product development, bad requirements can easily derail a project. We at Qualicen have been helping our customers now for over five years: both with our expertise
Mature Enough? Using Maturity Models to Assess and Improve Software Projects
It is not rare that projects approach us not as a consultant firm but more like a medical first-aid station. In those cases, the patient represents a software or engineering project that is hanging on by a bare thread. So
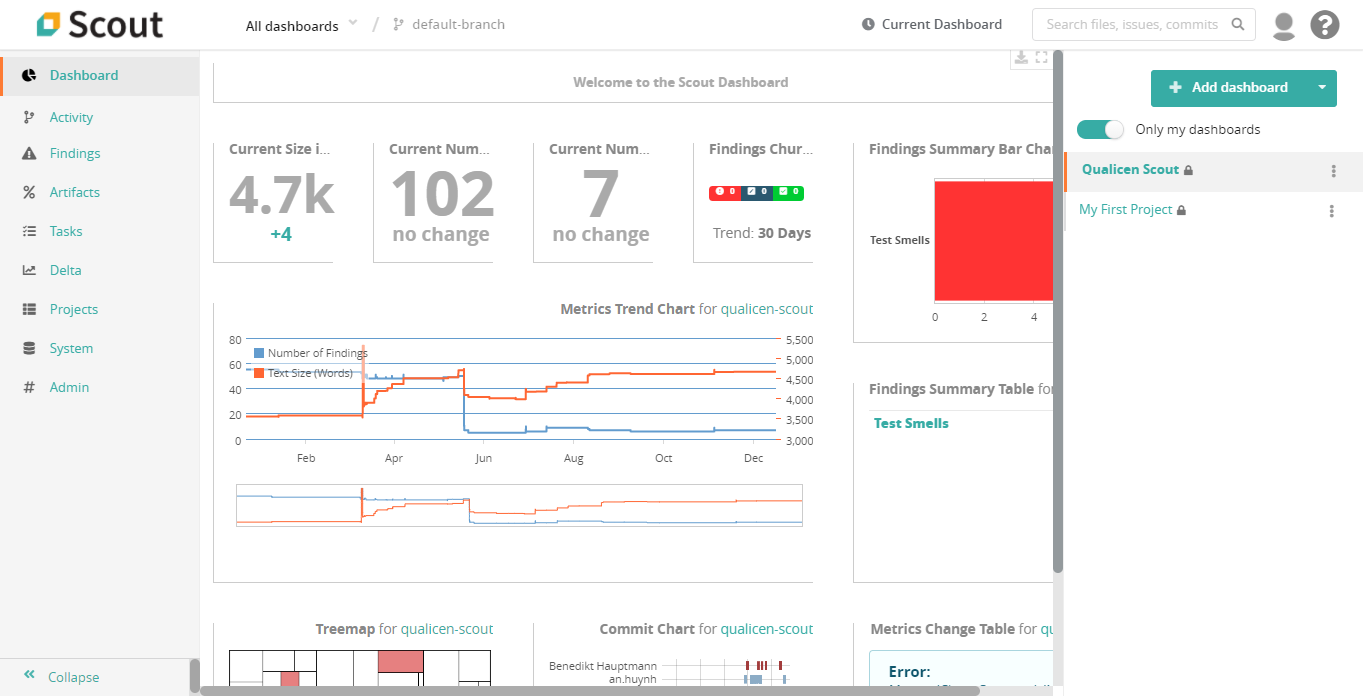
Release: Qualicen Scout 5.4-1
We are proud to announce the latest release of our automated quality analysis tool: Scout 5.4-1. In this release we incorporated many new features, and improved existing ones. In this blogpost we provide a brief overview of the most
Hey BERT, do you recognize any requirements?
Does scanning for your relevant requirements in massive documents sound familiar? In this blog post we are going to find them for you
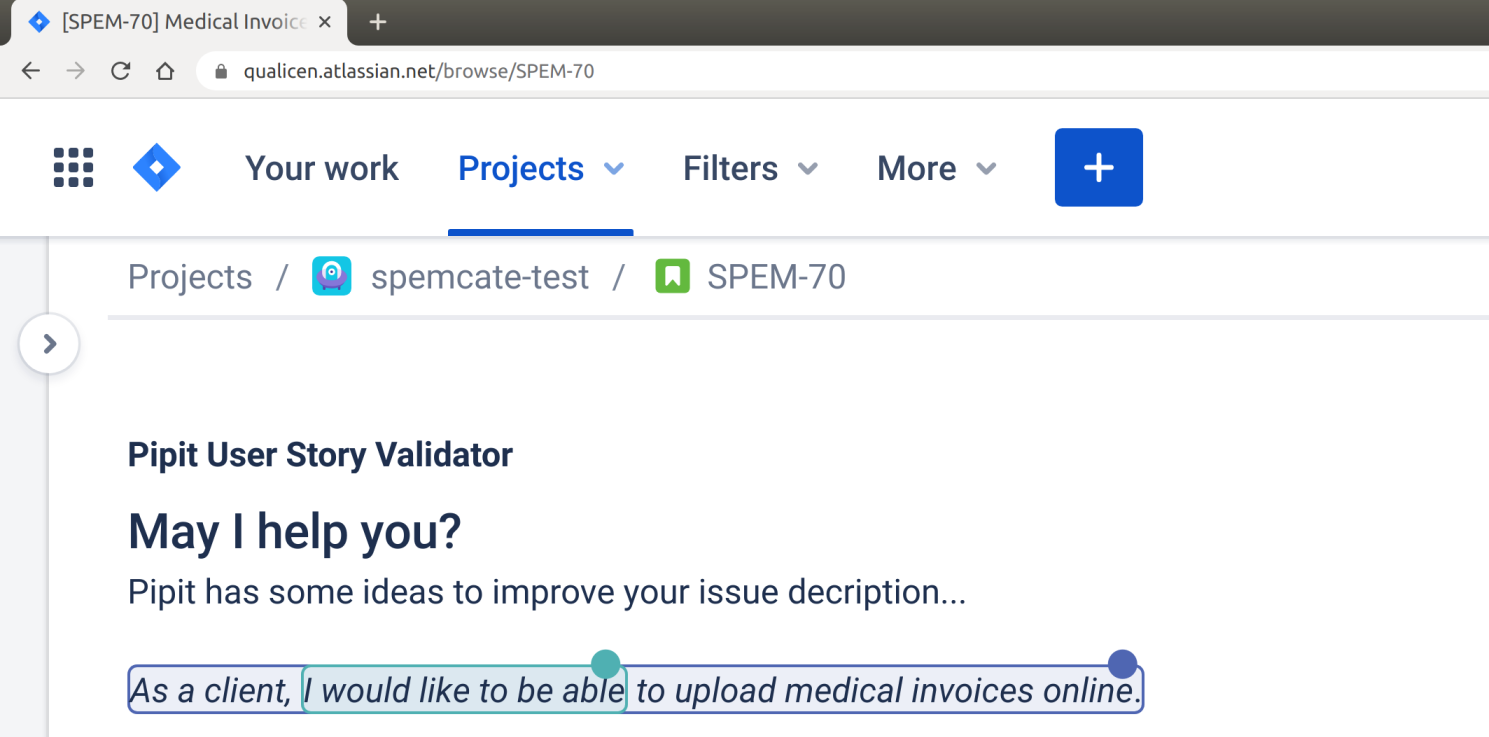
Introducing Pipit – The User Story Validator for Jira
User stories and acceptance criterias are the backbone of agile development. Everyone knows badly written user stories provide little value. In extreme cases, they even do more harm than good. Therefore, many best practices and templates exist guiding us to

How-to Requirement Reviews
Reviews! Either the safety net you always wanted or the hammer that knocks your teeth out. In this blog post we will explain how to conduct a valuable, effective and pleasant requirement review.

The Incredible Potential of Text Analytics – The Use Cases Explained.
New advances in text analytics make the tech news nearly every week, most prominently IBM Watson, but also more recently AI approaches such as ELMo or BERT. And now it made world news with the pandemic caused by the Covid-19 virus, with the white house requesting help via NLP.
Text Analytics and Natural Language Processing (NLP) deal with all types of automatic processing of texts and is often built on top of machine learning or artificial intelligence approaches. The idea of this article is not to explain how text analytics works, but instead to explain what is possible.
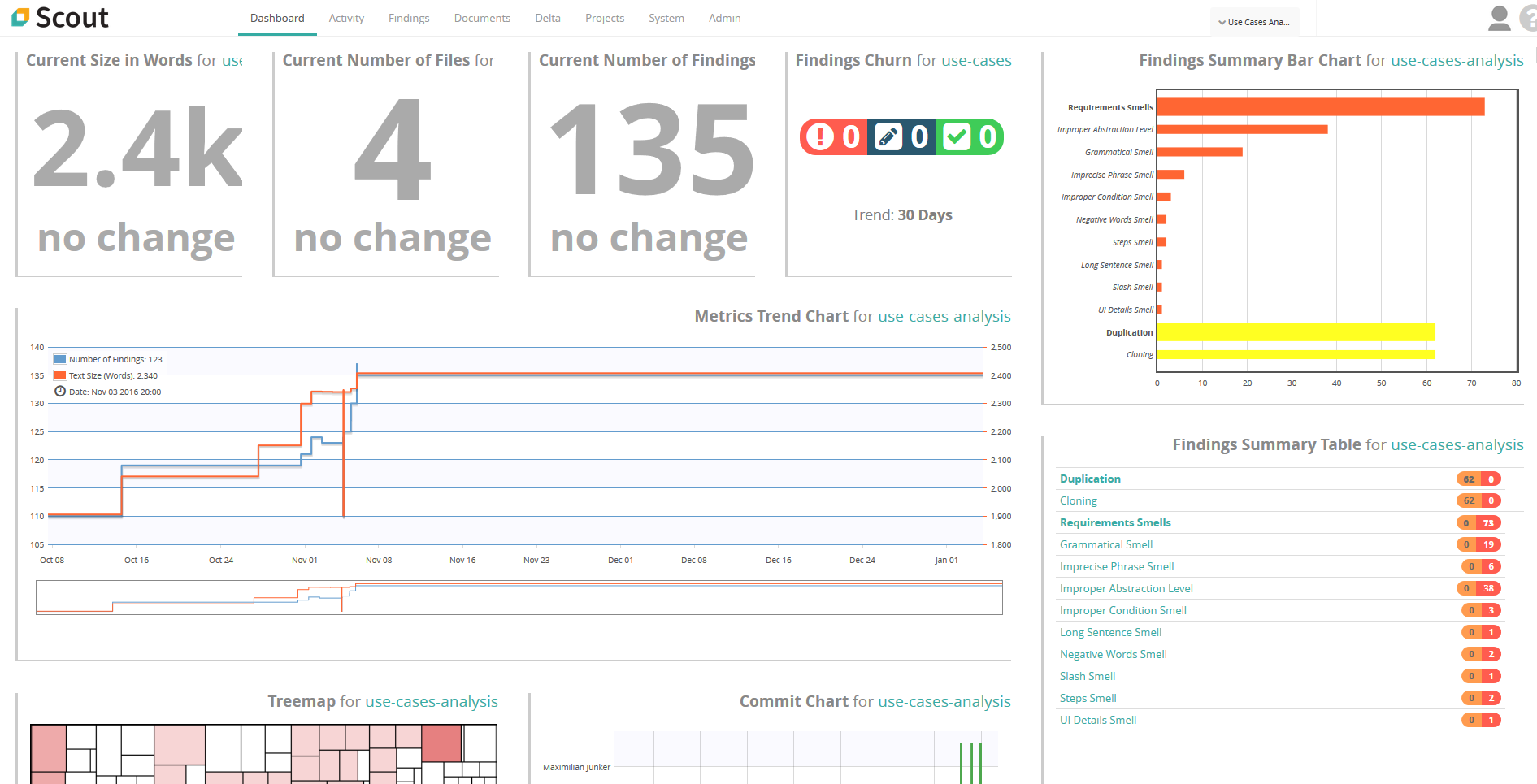
Release of Scout Version 4.6 (LTS)
If you ever had quality defects in your requirements-suite or test-suite, you know how time-consuming and expensive they can become. However, due to the sheer size of requirements-suites and test-suites, assessing the quality of the contained artifacts is almost impossible. So, is there no way out of this mess, or do you have to stick deep in this yogurt? There is help: The automated requirements and test analysis tool Scout by Qualicen comes now in a new and improved version!
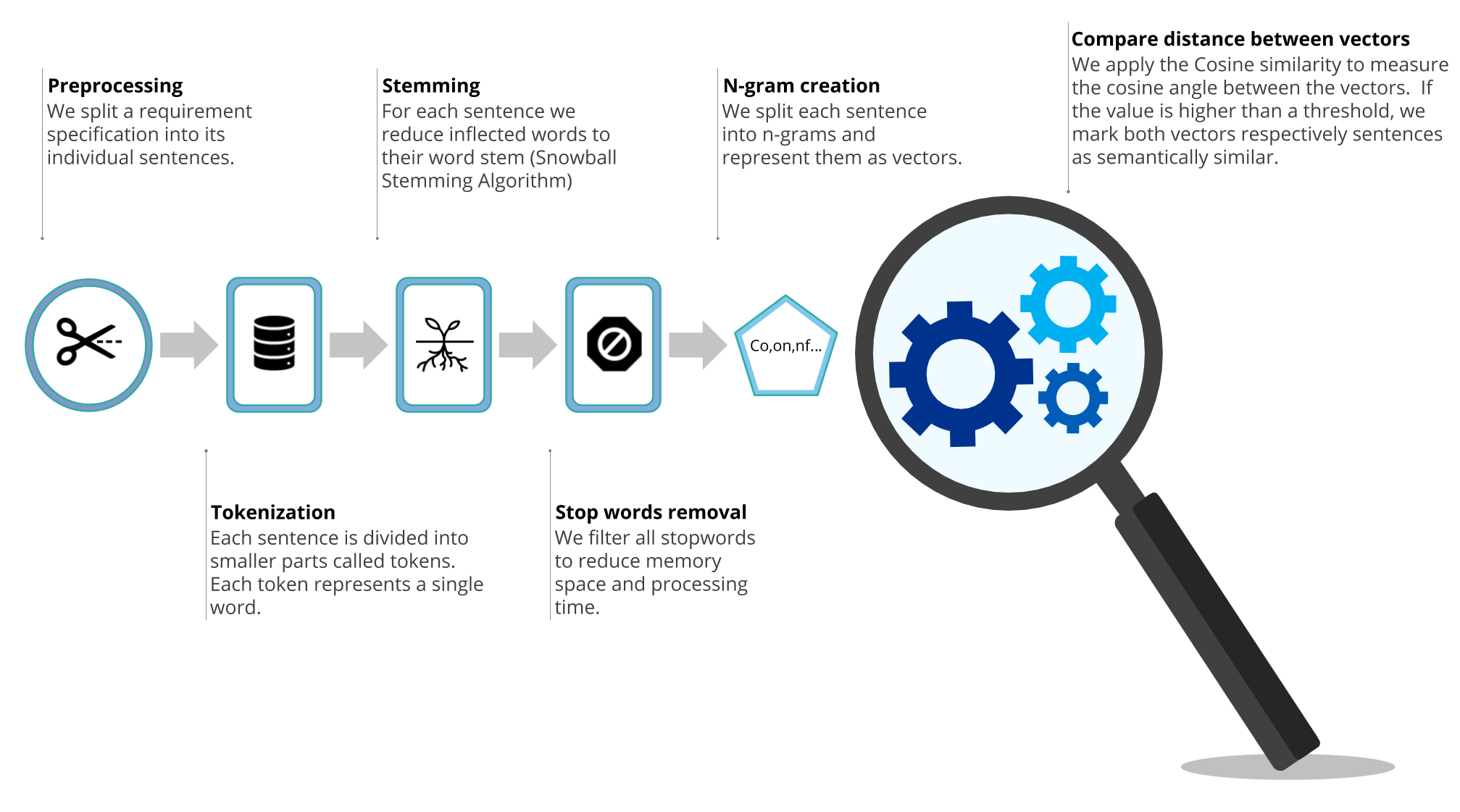
How to find semantic duplicates in requirements documents
Have you ever read a text and suddenly felt like you had a déjà vu? Maybe this happened because you came across a sentence that was very similar to one that you already read before. We call this semantic duplicates.
 Semantic duplicates can happen because we think one specific instruction is so important that we simply have to repeat it. But often semantic duplicates arise from simply copy-pasting text. First, semantic duplicates can lead to inconsistency within the requirements. In detail, if there are two similar sentences that explain the same requirement, the same requirement can be interpreted in two different ways. Second, if the sentences are not just similar, but rather a copy of each other, it makes the copy simply superfluous. However, semantic duplicates are redundant, which is why we decided to tackle this problem.
Semantic duplicates can happen because we think one specific instruction is so important that we simply have to repeat it. But often semantic duplicates arise from simply copy-pasting text. First, semantic duplicates can lead to inconsistency within the requirements. In detail, if there are two similar sentences that explain the same requirement, the same requirement can be interpreted in two different ways. Second, if the sentences are not just similar, but rather a copy of each other, it makes the copy simply superfluous. However, semantic duplicates are redundant, which is why we decided to tackle this problem.