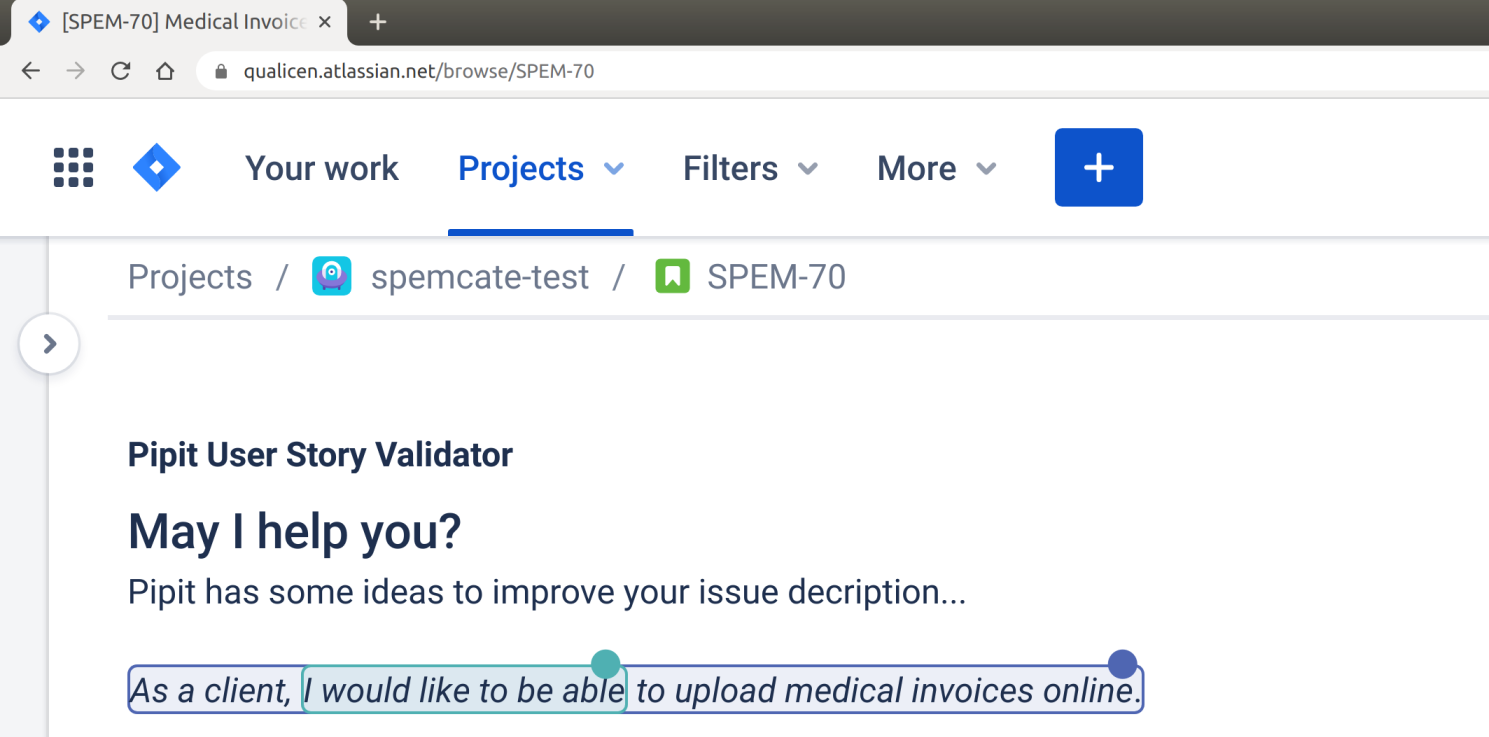
Introducing Pipit – The User Story Validator for Jira
User stories and acceptance criterias are the backbone of agile development. Everyone knows badly written user stories provide little value. In extreme cases, they even do more harm than good. Therefore, many best practices and templates exist guiding us to

Conference Report: QS-Tag Frankfurt
[caption id="attachment_9293" align="aligncenter" width="300"] Benedikt and Henning at our booth[/caption]
Last week, we were at QS-Tag in Frankfurt, Germany. QS-Tag is a great venue for testers and everyone else who is into Quality in Software Engineering. This year's topic was Expanding Horizons, but the actual topic was AI and Automation. We were present in two talks and I was invited to a panel discussion on the future of AI in Testing. Here are our key takeaways again:
Benedikt and Henning at our booth[/caption]
Last week, we were at QS-Tag in Frankfurt, Germany. QS-Tag is a great venue for testers and everyone else who is into Quality in Software Engineering. This year's topic was Expanding Horizons, but the actual topic was AI and Automation. We were present in two talks and I was invited to a panel discussion on the future of AI in Testing. Here are our key takeaways again:
BRAND NEW!!! Test Smell Plugin for VSTS DevOps
Test Smell Detection improves your manual test cases. The automatic detection of test smells helps making your test suite easy to understand and easy to maintain. In addition, the automatic detection also leads to consistent reproducible test results. The best way to find test smells is our Qualicen Scout. Scout can detect test smells in textual test descriptions automatically. Configured once, it immediately shows where you can improve your test descriptions. What kind of improvements you ask? Well, there is a wide variety of so called "Test Smells" Scout can automatically detect! Test smells are words, phrases, or language constructs that are not good for your test quality. For example, ...
- ambiguous phrases in your test descriptions (a threat to reproducible test results).
- sentences/paragraphs that are difficult to comprehend (prevents that your colleagues ask: "eh, what?")
- tests having multiple flows (shouldn’t a test focus on just one case?).
- steps that have been copied between test cases (super annoying to keep in sync when things change).
- and many more ...
Light-weight Requirements Modelling and Test Case Generation: Try it yourself!
Automatically generating test cases from requirements?
We show you how. For this, we created a new way to create lightweight models for requirements. The advantage of lightweight models over text: These models can automatically generate test cases. How awesome is that? Check out our youtube demo to see the system in action: [embed]https://www.youtube.com/watch?v=PlaOzUmVIcM[/embed] You can find more information in two blog posts: Part 1 and Part 2. Or, check out our live demo and try it yourself:How to automate Test-Design with Specmate – Part 2: End-to-End Testing of Business Processes
This article is a sequel to our blog post Structured Test-Design With Specmate – Part 1: Requirements-Based Testing published by my colleague Maximilian. So far, Maximilian introduced you to our tool Specmate - a tool that helps you to automate your test-design. He explained how to model requirements using cause-effect-models and how to automatically generate test specifications based on them. However, Maximilian told you only half the story (I’m sure you were already guessing that based on the Part 1 in the title. ;-) ): Not all requirements are like the ones in his examples. Many requirements are of a different nature and can’t be specified easily using cause-effect models. In this post, I’ll demonstrate the second way of modeling requirements in Specmate: Business processes. Furthermore, I show how to generate automatically end-to-end tests based on these business processes.
Moving in at GATE Garching (with Pictures!)
As most of you know, we moved to the GATE in Garching (a university town, 20 minutes out of Munich) recently. So in oder to celebrate our new offices, I wanted to share a few pictures from these days with you. We moved here in December. Engineers as we are, we loved all the assembling! And not too many things broke, actually ;) [gallery size="large" ids="451,450,459"]

Updates from Qualicen
Hey there! If you haven't heard from us at Qualicen in while it, it is because we are fortunately(!) very busy right now. Lot's of cool projects all over Germany and even up in Sweden. Contact us, if you would like to hear more about these projects or get in contact at one of the following venues.
Requirements quality is quality-in-use
I've worked quite some time on understanding and detecting quality defects in requirements documents and requirements quality in general. All the time, I was very dissatisfied with the current state in both research and practice on this topic. I think, the problem behind this is that there is no guidance: In times of rapid change and delivery, where every project looks different, we still have no good rule of what a good requirements document is. A few years ago, we came up with such a rule, and tried it in various applications. And - so far - it seems to work! We've collected this experience and are now ready to tell you about it, because we really believe this should change how you view requirements engineering, and this should change what you consider good requirements documents.

Automatic Feedback on TFS/VSTS Test Case Quality in Real Time
Team Foundation Server (TFS) and its software-as-a-service counterpart Microsoft Visual Studio Team Services (VSTS) are widely used application lifecycle management (ALM) and test management tools. They offer many great facilities to create tests, manage test plans, and execute them. Consequently, many of our clients as well as prospective customers wanted to use our test improvement software Test Scout along with TFS/VSTS to improve the test case quality. So, here is the question that we always face: How do we get the data from a testing tool into the Test Scout? As always in life, there is a straightforward and a fancy solution. Let me show you what I mean.
First: a simple integration
Test Scout is able to process almost any kind of text format. So, integrating test management tools such as TFS/VSTS is quite straightforward: For each test management tool, we created exports, which we imported into the Scout. For HP ALM, for example, we use a simple script to create a database dump containing all currently existing test cases. We then automatically imported and processed this data in Test Scout to evaluate the test case quality. Since Test Scout keeps versions of each import in its database, the history of all test cases is available in Test Scout. Therefore, all features, such as comparing different versions of test cases and historical development of test cases still works out of the box.
Efficiently control requirements quality: the best of two worlds
For high requirements quality we need quality assurance. In a previous post, I explained why automatic methods cannot replace manual methods. Instead I suggested to combine both worlds. And the ugly truth is, in both system testing and requirements engineering, we need both manual and automatic quality assurance to control requirements quality and test quality. Now you wonder, how? I got you covered. In this brief post, I want to point out how you can combine the two worlds and how you benefit from the combination.