
The Incredible Potential of Text Analytics – The Use Cases Explained.
New advances in text analytics make the tech news nearly every week, most prominently IBM Watson, but also more recently AI approaches such as ELMo or BERT. And now it made world news with the pandemic caused by the Covid-19 virus, with the white house requesting help via NLP.
Text Analytics and Natural Language Processing (NLP) deal with all types of automatic processing of texts and is often built on top of machine learning or artificial intelligence approaches. The idea of this article is not to explain how text analytics works, but instead to explain what is possible.
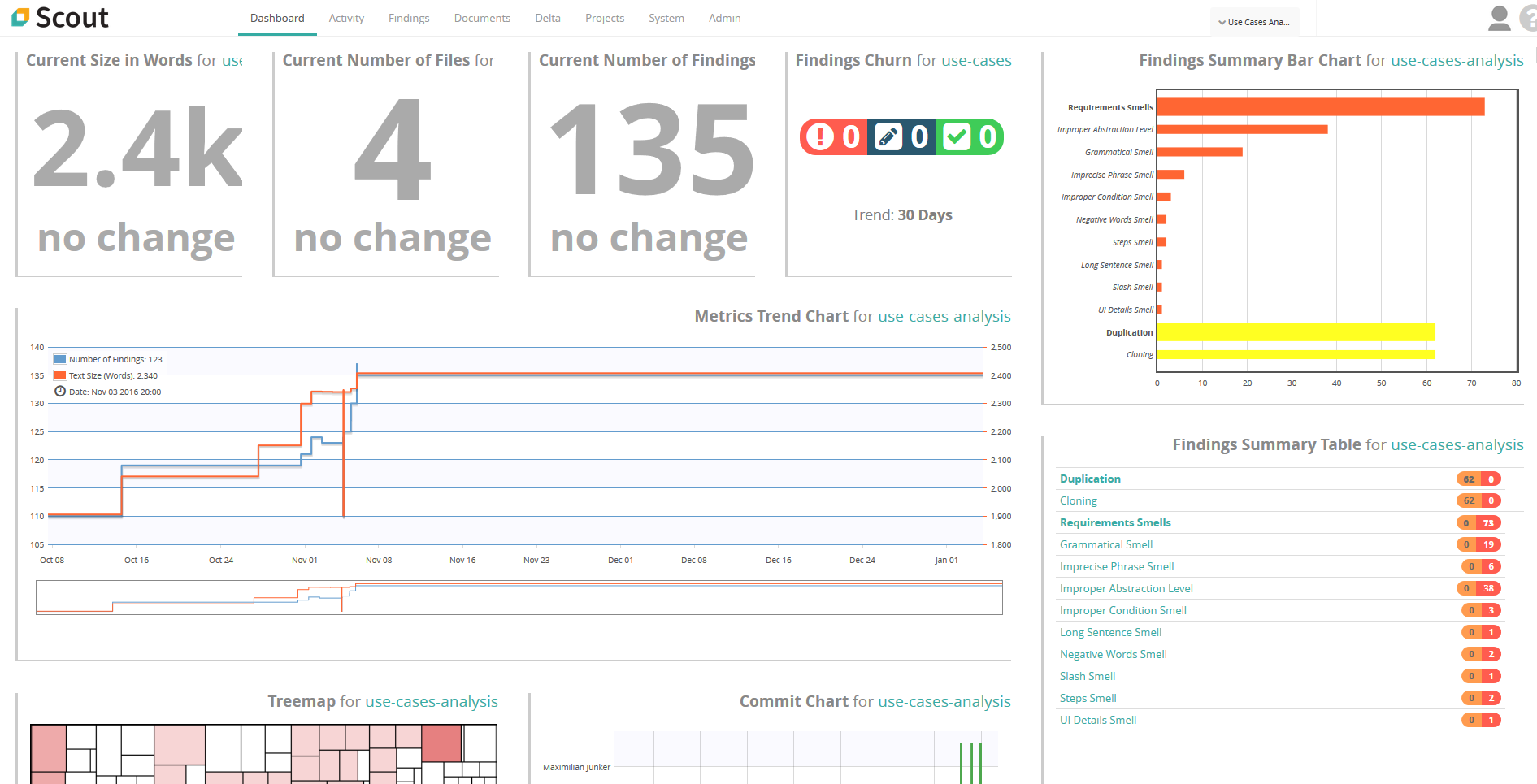
Release of Scout Version 4.6 (LTS)
If you ever had quality defects in your requirements-suite or test-suite, you know how time-consuming and expensive they can become. However, due to the sheer size of requirements-suites and test-suites, assessing the quality of the contained artifacts is almost impossible. So, is there no way out of this mess, or do you have to stick deep in this yogurt? There is help: The automated requirements and test analysis tool Scout by Qualicen comes now in a new and improved version!

A Gentle Introduction Of A Requirement Syntax
Requirement documentation is mainly done in either Natural Language (NL) or in formal models like UML or SysML. NL offers the lowest learning curve and the most flexibility, which for many companies means: "Everyone can start writing requirements without formal training".
In contrast, formal modelling languages require a considerable effort to learn and are very restrictive. But, the flexibility of NL comes with ambiguity and inconsistency. These are two major downsides that formal modeling languages aim to eliminate.
Our customers often ask: "Is there something in the middle, keeping the benefits of NL, but reducing the downsides?" our answer: "Yes, a requirement syntax". But what has that children's puzzle to do with writing requirements?
But what has that children's puzzle to do with writing requirements?
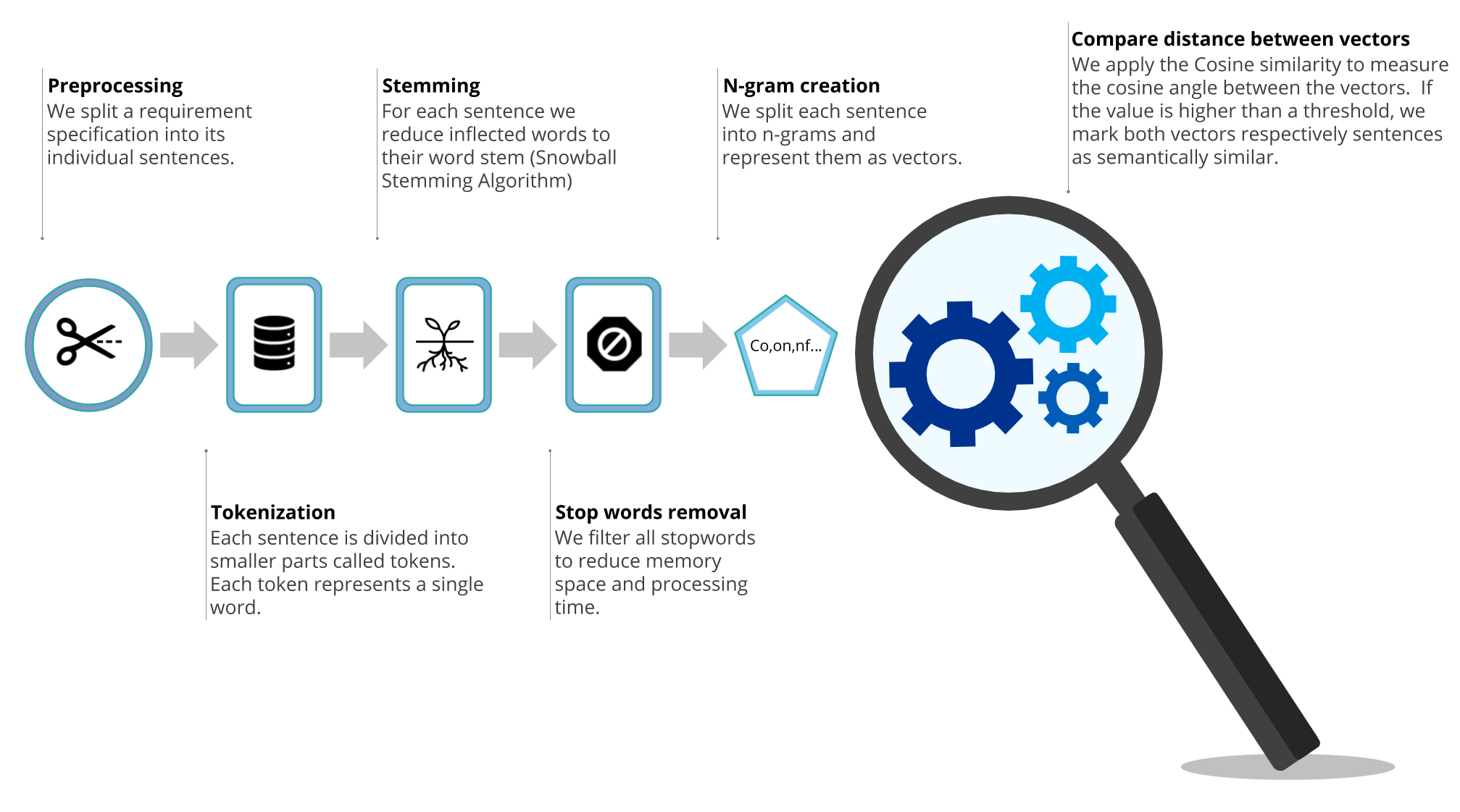
How to find semantic duplicates in requirements documents
Have you ever read a text and suddenly felt like you had a déjà vu? Maybe this happened because you came across a sentence that was very similar to one that you already read before. We call this semantic duplicates.
 Semantic duplicates can happen because we think one specific instruction is so important that we simply have to repeat it. But often semantic duplicates arise from simply copy-pasting text. First, semantic duplicates can lead to inconsistency within the requirements. In detail, if there are two similar sentences that explain the same requirement, the same requirement can be interpreted in two different ways. Second, if the sentences are not just similar, but rather a copy of each other, it makes the copy simply superfluous. However, semantic duplicates are redundant, which is why we decided to tackle this problem.
Semantic duplicates can happen because we think one specific instruction is so important that we simply have to repeat it. But often semantic duplicates arise from simply copy-pasting text. First, semantic duplicates can lead to inconsistency within the requirements. In detail, if there are two similar sentences that explain the same requirement, the same requirement can be interpreted in two different ways. Second, if the sentences are not just similar, but rather a copy of each other, it makes the copy simply superfluous. However, semantic duplicates are redundant, which is why we decided to tackle this problem.
Requirements Engineering and Origami
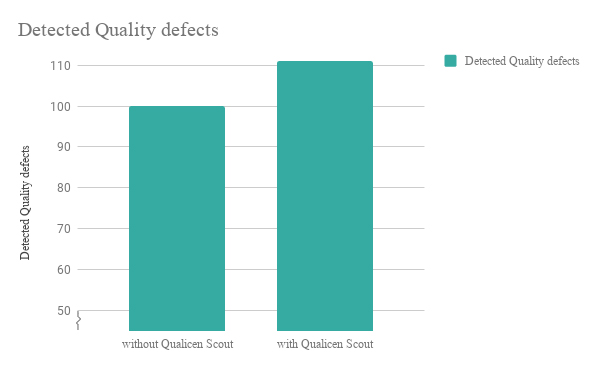
Detect more Quality Defects in your Requirements
How we investigated whether our Qualicen Scout is a useful tool for companies in the domains of software and systems engineering.
Why we wanted to answer this question
As science showed, the quality of the requirements documentation influences the subsequent activities of the software engineering process. Detecting errors late in a software engineering process leads to very expensive changes of parts of every pre-executed activity. Accordingly, we at Qualicen help our customers to assure the quality of requirements specifications before they are used in other activities.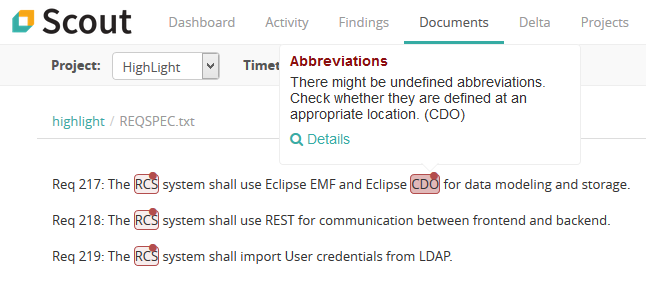
How to Awake Your Glossary From Zombie Mode
When we look at requirements documents that are new to us, we often need some help on terms and abbreviations. Creating a glossary to explain these imporant domain terms and abbreviations is a fine idea. It helps new team members to get going, improves the readability of a requirements specification and helps to avoid misunderstandings. The main problem with glossaries is that we create them once and update them only rarely. In consequence, the majority of glossaries are not particulary useful. In this article, Qualicen consultant Maximilian Junker shows how you can get more out of your glossary and keep it always up-to-date.