How to find semantic duplicates in requirements documents
Have you ever read a text and suddenly felt like you had a déjà vu? Maybe this happened because you came across a sentence that was very similar to one that you already read before. We call this semantic duplicates.

Semantic duplicates can happen because we think one specific instruction is so important that we simply have to repeat it. But often semantic duplicates arise from simply copy-pasting text. First, semantic duplicates can lead to inconsistency within the requirements. In detail, if there are two similar sentences that explain the same requirement, the same requirement can be interpreted in two different ways. Second, if the sentences are not just similar, but rather a copy of each other, it makes the copy simply superfluous. However, semantic duplicates are redundant, which is why we decided to tackle this problem.
Semantic Duplicate Smell in Qualicen Scout
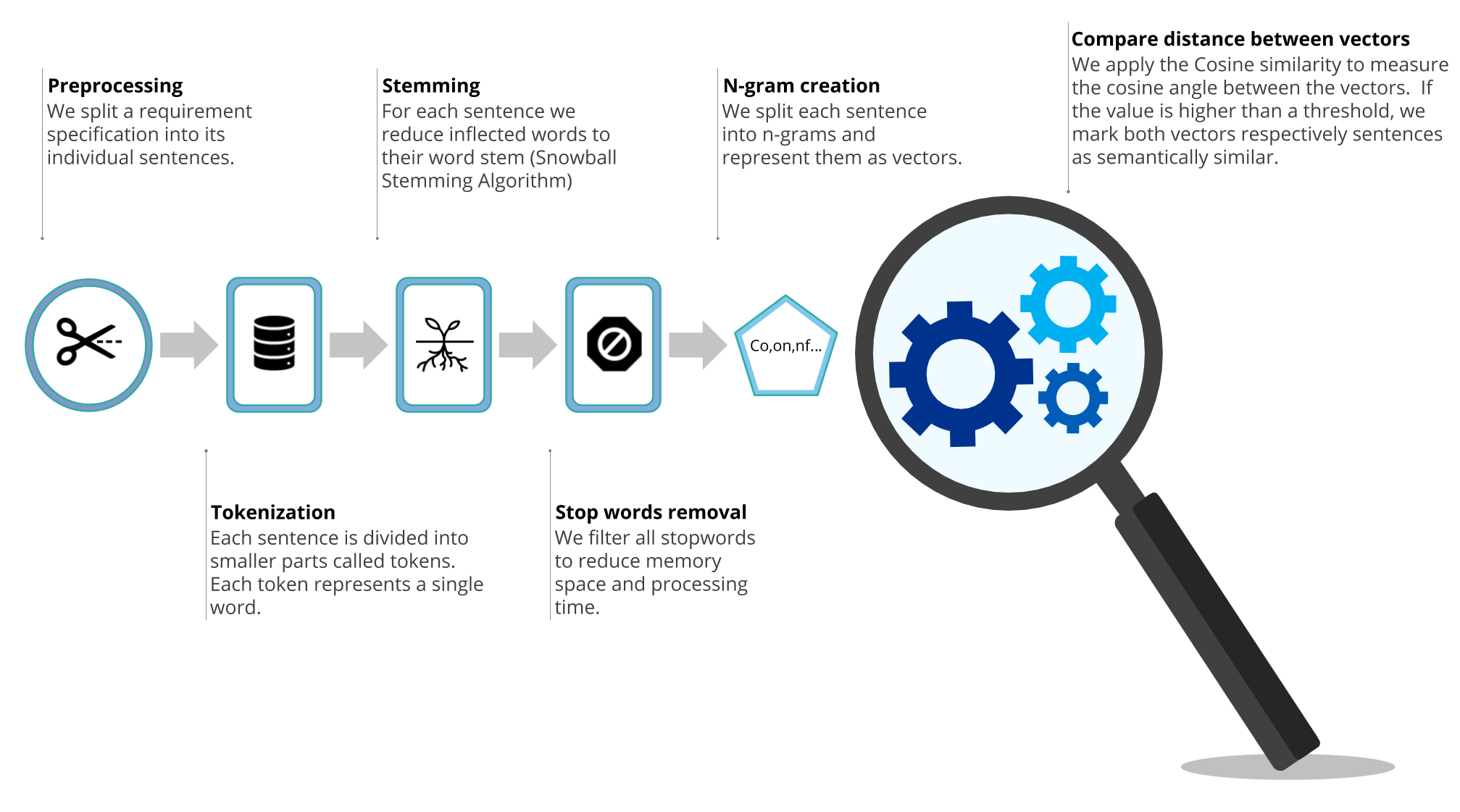
By enabling the semantic analysis chain, every Qualicen Scout user is able to compare sentences for similarity document-wide and also over different documents. The smell runs within the requirement profile of Scout and the description of the smell tells us which sentences is the apparent duplicate. The following picture gives a short description about the processing pipeline that runs within our Scout.
Now we know that we can detect semantic duplicates, and maybe have a shallow understanding how we do it. But how does the detection actually work in detail?
From requirements to semantic duplicates
To detect semantic similarities we first apply the common nlp-tools, like sentence splitting, tokenization, stemming and stop word removal. Afterwards we split the sentences into n-grams. To improve generalization and robustness we apply several n-grams, like 2-grams and 3-grams, onto the sentences. We compute the n-grams by splitting up the sentence into character sequences with n length. We demonstrated an example with three short sentences and 2-grams in the following table:

To compare the similarity of sentences, all in the sentences contained n-grams are stored in a list. It is important that each n-grams is unique in the list. Therefore the list of 2-grams contains “ll” only once, even though the sentence includes “ll” twice. From the list of n-grams, we can compute a term frequency (TF), by counting the number of occurrences of each n-gram in a sentence. The example table shows already the computed TF. By computing the term frequency of the n-grams for each sentence, we build two vectors. We then compare these vectors with the cosine similarity. The cosine similarity of two vectors A and B are computed with the following formula:
![]()
For our specific example this results in the following values:
![]()
![]()
We detect a semantic duplicate if the cosine similarity exceeds a certain threshold. For the example in the table, the sentences A and B would be detected as duplicated, but A and C not, as they are not alike at all. By the way, this threshold and also the list of n-grams that should be used, can be individually set within the analysis profile of our Qualicen Scout.
TL;DR
We tend to integrate semantic duplicates into our requirements, but now Qualicen Scout is able to detect them. With a processing pipeline that includes common NLP, n-gram creation, and the calculation of the cosine similarity between requirement sentences, Scout is able to tell you if two sentences are semantic alike. However, semantic duplicates are redundant and should be avoided from the outset.



Sorry, the comment form is closed at this time.
Pingback: How-to Requirement Reviews – Qualicen
23/06/2020