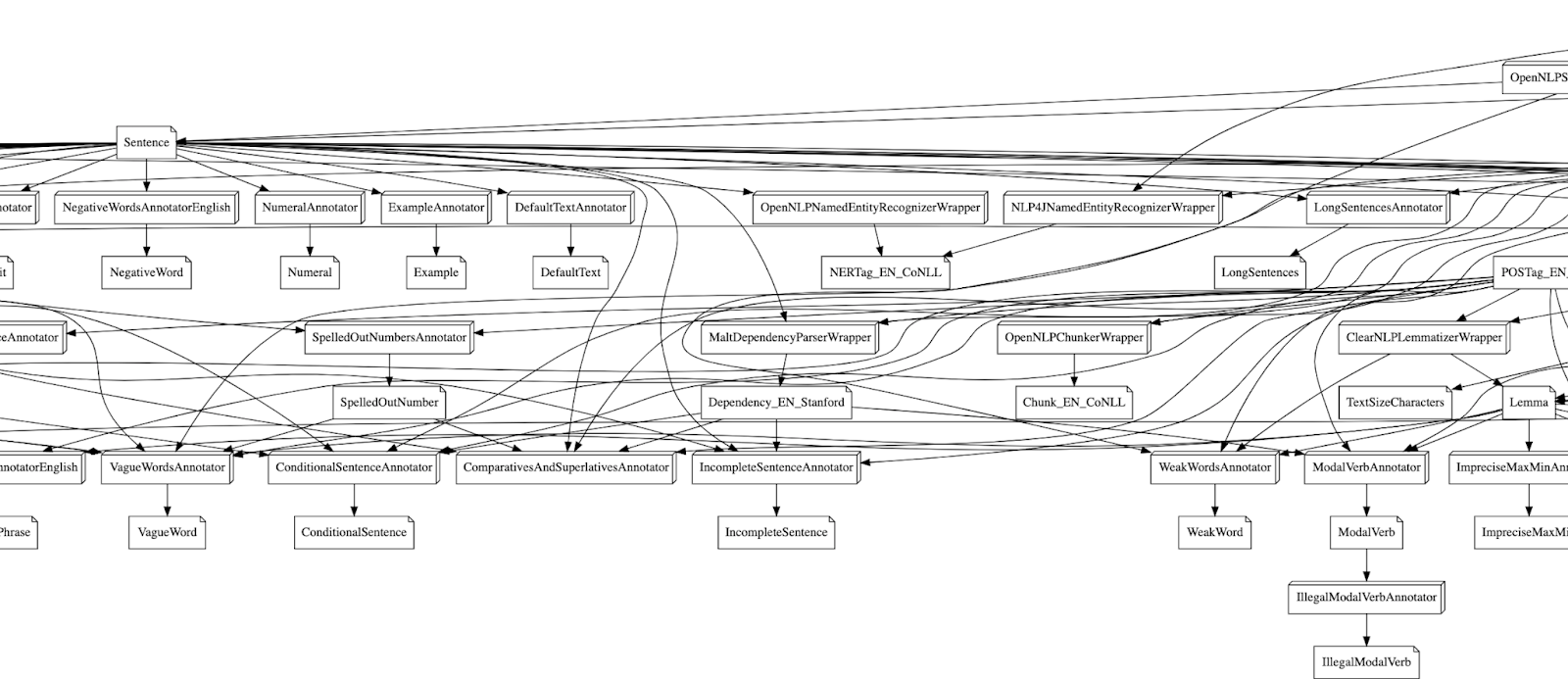
The Great Pipeline – How Holmes Selects its Annotators
In a previous blog post we have discussed the development of our NLP library Holmes and how it chains together simple annotators to do complex text analyses. One of the big challenges we faced while development, was figuring out how to deal with annotator dependencies:
The core functionality of Holmes is provided by annotators. Each annotator has a simple task like identifying sentences, doing part-of-speech tagging, or finding spelling errors.
But most of them can’t run without some other annotator running beforehand: You can’t tag parts-of-speech without identifying the tokens of a text. Finding long sentences requires finding sentences first.
At the same time we wanted to make it easy for you to configure the pipeline. The goal was that you only have to configure the annotators you want without having to handle all the dependencies. So if you want long sentence detection but you did not configure how Holmes finds sentences in the first place, Holmes itself should pitch in and do it.
While the concept of “only configure what you need” is nice if you are a user. From the perspective of a Holmes developer it was challenging. So here is with what we came up:

Into NLP 6 ~ New Link Project – Dependency Parser
Today we will talk about one of my favorite tools from the toolbox of classical NLP: The Dependency Parse. Dependencies can help us analyze the grammatical structure of a text. This is incredibly useful since we can use it to

Into NLP 5 ~ Numerous Language Parts – POS Tagging
Last time we had a look at the task of text normalization as a way of simplifying matching and searching for certain words. I mentioned that for the more complex normalization techniques one needs additional information: Since nouns, verbs, and

Into NLP 4 ~ Normal Language Perfection – Text Normalization
In my last article I talked about the benefits of tokenization regarding text processing: Essentially when we want to make processing text less awkward by separating tokens / words from the whitespace. In this article we continue cleaning up after
Into NLP 3 ~ Numerous Language Pieces – Tokenization
Previously we started our journey into the world of Natural Language Processing by learning the basics of Regular Expressions (RegEx) and fuzzy matching. While RegEx is certainly a powerful tool, it has its problems. As I wrote, Regular Expressions have a

Into NLP 2 – Fuzzy String Matching and the Edit Distance
NearLy Perfect In my last article I started with a dive into the wonderfull world of Regular Expressions. We’ve seen how RegEx are really useful for search tasks. However… They are not perfect and today we will look at one particular

Into NLP 1 – Regular Expressions
Into the Fire - A no less somewhat less nonsense introduction to NLP
Natural Language Processing? - What is NLP?
Language is messy. In our attempts to convey meaning, and emotions to each other, we have come up with some extraordinarily complex structures that need years of learning to grasp. There are countless rules and even more exceptions to those rules but somehow we manage to communicate with each other. The name, scientists have come up with for mess is natural language.
And then there are computers, machines that require a lot of structure to work. NLP is the attempt to make those two worlds meet, to have computers parse, process, and understand the language we use in our daily (natural) lifes. In the coming articles we will have a look at tools, techniques, and methods that help us deal with the chaotic complexity of natural language. We will see the many ways in which NLP will make dealing with language easier, one method at the time. Today we will start with the first:
Regular Expressions

Turbocharging Textsearch with NLP
Searching through a piece of text doesn’t sound like a task one would need a lot of fancy NLP technology for, but we recently had a case where this was actually necessary:
One of our customers asked us if we could help them with searching for specific terms in their documents. Their task was to deal with contracts and requirements, where missing even a small detail can potentially cost millions down the line. Additionally, these documents are usually very long, sometimes several thousands of pages. So if one where to simply Ctrl + F for a specific term one might get hundreds and hundreds of results, most of which irrelevant.

OTTERs and the Theory of Automatic Testgeneration
Creating test cases by hand can be a lot of effort. It takes time, and so costs plenty of money. It is estimated that testing on average costs roughly 50% of the project budget.So maybe, we could try and skip it? Well, we still need to test and, among other things, make sure that the system behaves in the way we specified. But maybe we can develop an automatic method for creating tests? And this is the core idea: Why not use the specification to generate the tests?

Detecting Cause-Effect Relations in Natural Language
Anyone who has used a recent version of Specmate might has already seen an amazing new feature. In the overview screen of any Cause-Effect-Graph is now an anoccurus little button titled “Generate Model”. Clicking this button will trigger a chain of systems, that is capable of using natural language processing to turn a sentence like
If the user has no login, and login is needed, or an error is detected, a warning window is shown and a signal is emitted.directly into a CEG, without any additional work from the user:
 In this article we will do a deep dive into this feature, have a look at the natural language processing (NLP) pipeline required to make such a system work, see different approaches to implement it, and figure out how to garner the power of natural language processing for our goals.
In this article we will do a deep dive into this feature, have a look at the natural language processing (NLP) pipeline required to make such a system work, see different approaches to implement it, and figure out how to garner the power of natural language processing for our goals.