The Great Pipeline – How Holmes Selects its Annotators
In a previous blog post we have discussed the development of our NLP library Holmes and how it chains together simple annotators to do complex text analyses. One of the big challenges we faced while development, was figuring out how to deal with annotator dependencies:
The core functionality of Holmes is provided by annotators. Each annotator has a simple task like identifying sentences, doing part-of-speech tagging, or finding spelling errors.
But most of them can’t run without some other annotator running beforehand: You can’t tag parts-of-speech without identifying the tokens of a text. Finding long sentences requires finding sentences first.
At the same time we wanted to make it easy for you to configure the pipeline. The goal was that you only have to configure the annotators you want without having to handle all the dependencies. So if you want long sentence detection but you did not configure how Holmes finds sentences in the first place, Holmes itself should pitch in and do it.
While the concept of “only configure what you need” is nice if you are a user. From the perspective of a Holmes developer it was challenging. So here is with what we came up:
Annotating Annotation Annotators
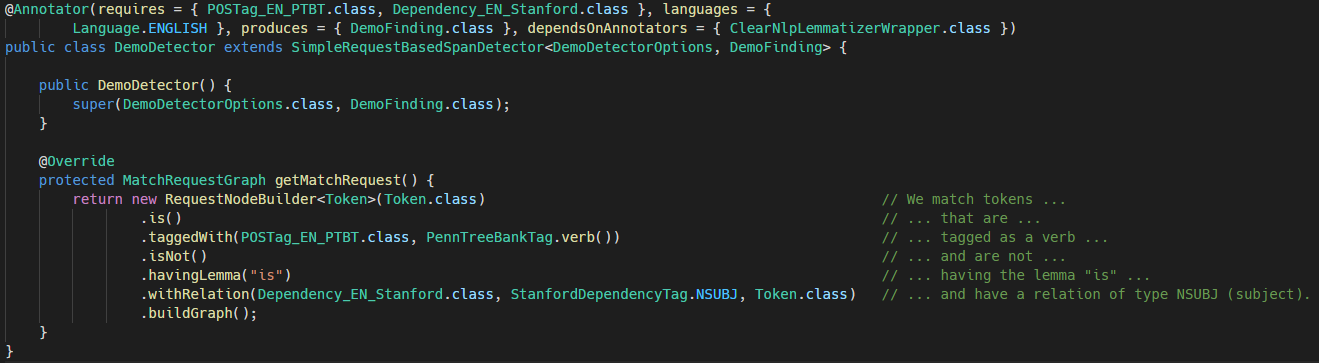
In order to get a handle on the problem we started by adding an annotation to each of our annotators. It provides four pieces of information:
- Which languages are supported by the annotator
- Which annotations the annotator needs in order to run
- Which annotators have to run for this annotator to be able to run
- Which annotations are produced by this annotator
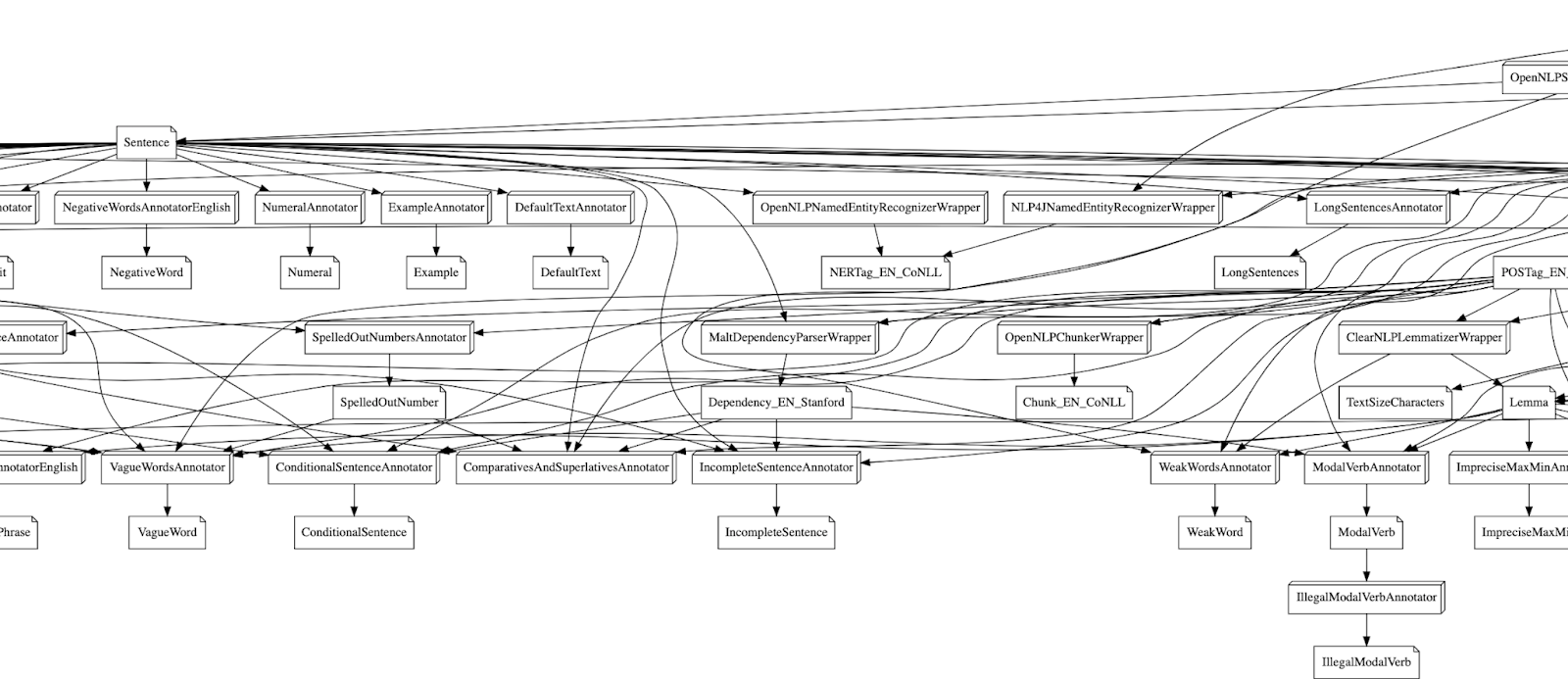
From this, we can build a dependency tree. Where we have a node for each annotator and annotation and an edge if the annotation is produced or required by another annotator. So if we do this it looks a little like this:

And if we zoom in a little:
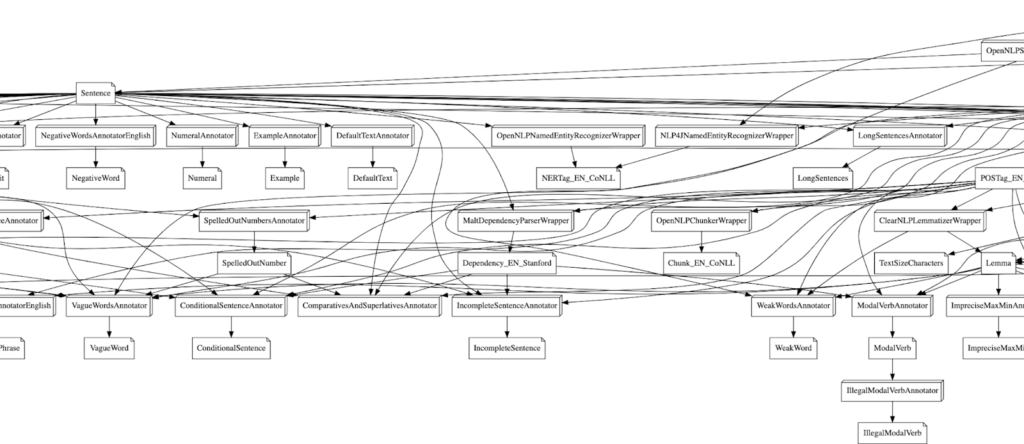
Well… This doesn’t make it a lot easier, does it? At the time of writing the graph has 138 vertices and 215 edges. Sure we could try and run some graph algorithm on this to resolve all the dependencies but it will be messy because there are a lot of constraints baked into this graph:
- Each annotation may only be produced once. So no two annotators that produce the same annotation are allowed to be part of the solution.
- Each annotator may only run after all of its required annotations have been produced and all of its dependencies have ran
- We need all the annotators selected by the user (you) to run
- We want to run as few annotators as possible
- We want to run multiple annotators in parallel where possible
All of these constraints make writing a graph algorithm to deal with this mess quite tricky but there is a solution: Constraint Satisfaction Problems(CSPs). But what is that?
The mystical CSPs
Constraint Satisfaction Problems are at its core quite simple: We define some variables, and some constraints for those variables. We hand it off to a solver. The solver finds an optimal solution. Badabing Badabum! – Problem Solved.
But when you try to actually do it, it can still be tricky. So how does the CSP of Holmes look like?
A simplified Example
First let’s look at a simplified example where we don’t care about the order in which the annotators have to run.
For each annotator we just have a boolean variable: An annotator either runs or it doesn’t. The same is true for annotations. The annotation is either produced or it isn’t
Then we can start modeling the constraints so if the “Long Sentence Annotator” requires the “Sentence Annotation” we have the constraint:
“Long Sentence Annotator” ⇒ “Sentence Annotation”
Similarly, if we have three different segmenters (“Segmenter A”, “Segmenter B” and “Segmenter C”) where each of them is able produce the “Sentence Annotation”, we have something like:
“Sentence Annotation” ⇔ “Segmenter A” or “Segmenter B” or “Segmenter C”
Additionally we have to have the condition that we can only use one segmenter:
AtMostOne(“Segmenter A”, “Segmenter B”, “Segmenter C”)
Lastly we need to make sure that if the user has selected the “Long Sentence Annotator” to run, it must be that
“Long Sentence Annotator” = True
This logic tells us which annotators and annotations have to be part of the pipeline but it does not tell us the order. This is critical: Just because we can find producers for each annotation does not mean that we can find an order in which they can run. In theory we could have circular dependencies.
So we have another set of time variables which tell us: When does the annotator run?
Their constraints are defined in a similar fashion as the ones above.
Lastly we need to tell the solver a goal function to optimize. In our case it is the number of annotators that will run and that we want to minimize this number.
And then all that’s left is just to feed this into a CSP solver and we get exactly which annotators and annotations have to be present and when they run.
And that’s the entire magic behind the Holmes pipelining which enables you to easily configure Holmes for your NLP project. Sure it was not easy by all accounts but it makes it a lot easier for you to always get what you need and this is why we’ve put a lot of energy into it. If we’ve peeked your interest and you want to try Holmes for yourself. You can contact Sebastian Eder for evaluation licenses.