The Great Pipeline – How Holmes Selects its Annotators
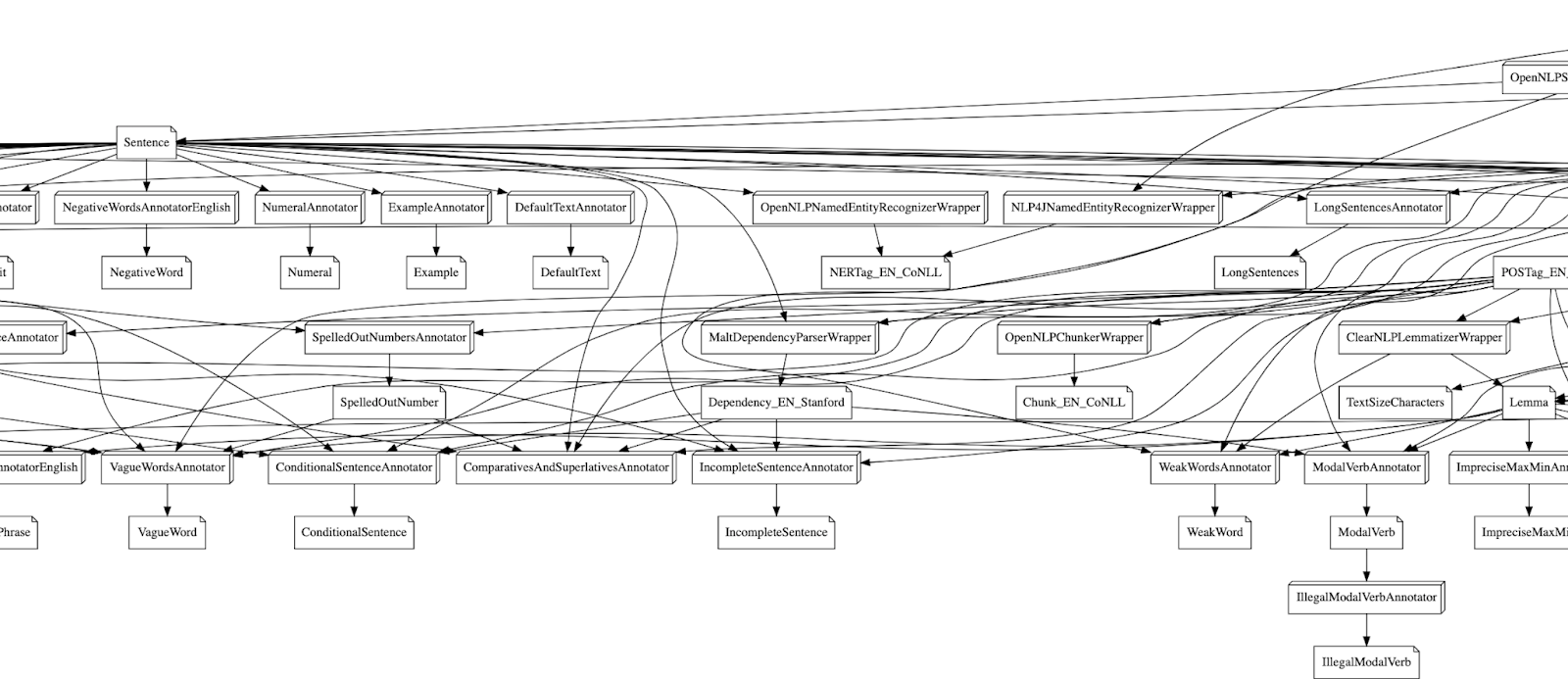
In a previous blog post we have discussed the development of our NLP library Holmes and how it chains together simple annotators to do complex text analyses. One of the big challenges we faced while development, was figuring out how to deal with annotator dependencies:
The core functionality of Holmes is provided by annotators. Each annotator has a simple task like identifying sentences, doing part-of-speech tagging, or finding spelling errors.
But most of them can’t run without some other annotator running beforehand: You can’t tag parts-of-speech without identifying the tokens of a text. Finding long sentences requires finding sentences first.
At the same time we wanted to make it easy for you to configure the pipeline. The goal was that you only have to configure the annotators you want without having to handle all the dependencies. So if you want long sentence detection but you did not configure how Holmes finds sentences in the first place, Holmes itself should pitch in and do it.
While the concept of “only configure what you need” is nice if you are a user. From the perspective of a Holmes developer it was challenging. So here is with what we came up:
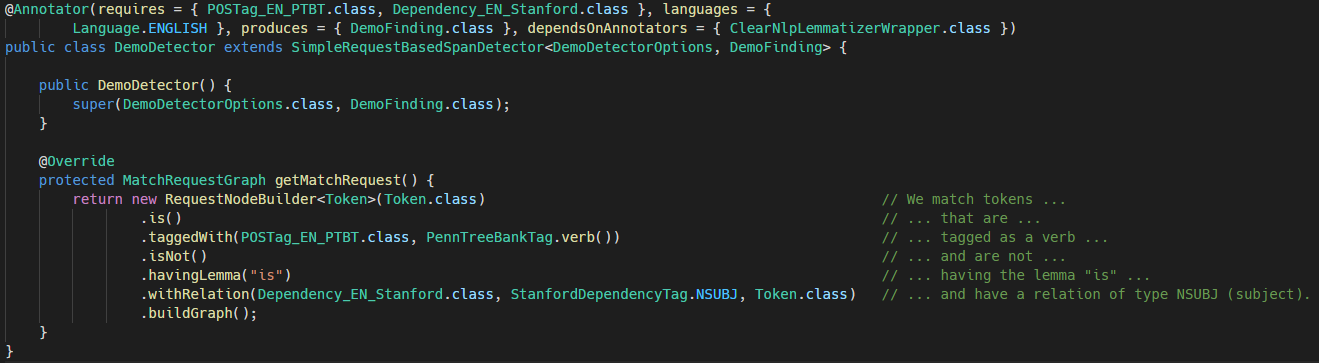
Our New Library for State-of-the-Art Natural Language Processing
There is a plethora of NLP libraries out there. For almost every NLP task, be it from rather trivial things like stop word removal, to more complex operations like relation extraction, there are libraries. This yields enormous power for modern