Our New Library for State-of-the-Art Natural Language Processing
There is a plethora of NLP libraries out there. For almost every NLP task, be it from rather trivial things like stop word removal, to more complex operations like relation extraction, there are libraries. This yields enormous power for modern software applications.
However, the APIs and interfaces of the different libraries greatly vary in style, precision and usability. In addition, in some cases it is cumbersome and frustrating to get even just trivial things to work. There are mainly two reasons for this:
- The libraries do not share a common data model and converting the data from one library to the other is error prone and boring.
- Interpreting and mining the results of the different libraries is cumbersome and varies between the libraries. In many cases, searching the results for specific terms, phrases, sentences, or other text blocks with specific features is hard to implement, slow and tedious.
Of course, there are frameworks already taking the challenge of unifying all the colourful NLP libraries. One example is DKPro – don’t get me wrong, the whole DKPro ecosystem is great and very helpful with many NLP tasks. However, in our opinion and for our applications, DKPro and its companions do only half of the job. We are missing the following:
- Extensibility: Most of the libraries lack an easy mechanism to be extended. This makes it hard to create own implementations of custom NLP tasks.
- Some NLP tasks need other NLP tasks to be run before them to have all data present they need. Thus, there are dependencies between the tasks. It is tedious to always find the correct dependencies and make them run.
- An easy and fast way to search annotated texts for words, phrases, sentences or other text blocks with certain and sometimes complex characteristics, e.g., navigating through UIMA annotations finding certain annotated words is hard to implement, error prone and usually slow.
Holmes
This is why we created a new library for all the NLP tasks out there: Holmes. Within Holmes, which is written in Java, we provide so far:
- Simple NLP-Task implementation
- Automated pipeline generation
- Intuitive and fast result queries
In the remainder, I will illustrate how you can use these features. As an example, we will build a Detector, that finds all long sentences in a given text in English language.
How to use Holmes
To create your own NLP-Task, you just need to do the following:
- Make your class inherit from
AnnotatorBaseor any of its subclasses, e.g.TagAnnotatorBase - Add the
@Annotatorannotation and provide information about which annotations your NLP task will produce (LongSentenceFinding) in the example, and which annotations your task needs in order to work properly (Sentence.class) in the example. Based on this information, Holmes will build whole NLP pipelines automatically. - Implement the
getAnnotatorResults-method (we will come to that in a second). - Provide an options class with the configuration options you NLP-task will accept. This just needs to extend
ReferenceBaseor any of its subclasses, e.g.TagAnnotation. - Provide an annotation class your task will produce. This class needs to extend
AnnotatorOptionsBaseand implement the methods for providing a name and a message for the annotation.
For illustration, we will implement an annotator that detects sentences that are longer than a certain threshold of characters. This annotator will mark all long sentences with a LongSentenceFinding and can be configured via LongSentencesDetectorOptions. In the following examples, you can see that sentences that are longer than 30 characters will be marked.
This is a sentence that is longer than 30 characters.
This sentence is short.
But this sentence is longer than the threshold.
The method getAnnotatorResults retrieves one argument, a search structure called ACS (Annotation Collection Structure). In our case, we use the structure to find everything that is annotated with Sentence by calling acs.getCollection(Sentence.class). We iterate through the sentences and add annotations by calling this.createAnnotation(sentence.getTextIndexBegin(), sentence.getText()) and adding this to our results vector.
@Annotator(requires = { Sentence.class }, produces = { LongSentencesFinding.class })
public class LongSentencesDetector extends TagAnnotatorBase<LongSentencesDetectorOptions, LongSentencesFinding, Sentence> {
public LongSentencesDetector() {
super(LongSentencesDetectorOptions.class, LongSentencesFinding.class, Sentence.class);
}
@Override
protected Collection<LongSentencesFinding> getAnnotatorResults(@NonNull ACS acs) {
final Vector<LongSentencesFinding> result = new Vector<LongSentencesFinding>();
final DataCollection<Sentence> sentences = acs.getCollection(Sentence.class);
for (final Sentence sentence : sentences) {
final int length = sentence.getText().length();
if (length >= this.getOptions().getLength()) {
result.add(this.createAnnotation(sentence.getTextIndexBegin(), sentence.getText()));
}
}
return result;
}
}
public class LongSentencesFinding extends TagAnnotation<Sentence> {
public LongSentencesFinding(DataCollection<? extends Tag<Sentence>> collection, @NonNull Sentence element) {
super(collection, element);
}
}
@Getter
@Setter
public class LongSentencesDetectorOptions extends AnnotatorOptionsBase {
@NonNull
private String name = "Long Sentences";
@NonNull
private String message = "The sentence is longer than the threshold.";
private int length = 30;
}
Automated Pipeline Generation
You might ask yourself how to call your annotators. We will perform few steps to do so:
- Build a pipeline containing all annotators you would like to execute
- Run the pipeline
We just saw that our LongSentenceDetector required annotations of the type Sentence to work properly. You will ask yourself where these annotations should come from. The good news here is: Holmes will provide these annotations as soon as you call your detector within a pipeline.
In the examples, we first instantiate our annotator and initialize a new analysis with our detector as the only detector that is mandatory for us to run. After running the analysis, we get an ACS as a result and easily query for our findings.
final LongSentencesDetector detector = new LongSentencesDetector();
final TextAnalysis analysis = new TextAnalysis(Collections.singleton(detector), Language.ENGLISH);
final ACS acs = analysis.analyze("This is my awesome sentence that might or might not be longer than the threshold.");
final List<LongSentencesFinding> findings = acs.getCollection(LongSentencesFinding.class).asList();
final LongSentencesDetector detector = new LongSentencesDetector();
final LongSentencesDetectorOptions options = new LongSentencesDetectorOptions();
options.setLength(10);
detector.setOptions(options);
final TextAnalysis analysis = new TextAnalysis(Collections.singleton(detector), Language.ENGLISH);
final ACS acs = analysis.analyze("This is my awesome sentence that might or might not be longer than the threshold.");
final List<LongSentencesFinding> findings = acs.getCollection(LongSentencesFinding.class).asList();
Result Queries
For now, we just wrote and executed an analysis that detects long sentences on a character level. This is not really natural language processing and could be done a lot easier. However, performing complex natural language processing tasks usually is cumbersome. Therefore, we developed a query language that allows you to intuitively specify patterns including NLP features to find the words or phrases you are searching for fast.
Note that you perform these queries on the ACS again. Thus, you can use these queries virtually everywhere you get in touch with analysing text: In annotators or after running a pipeline.
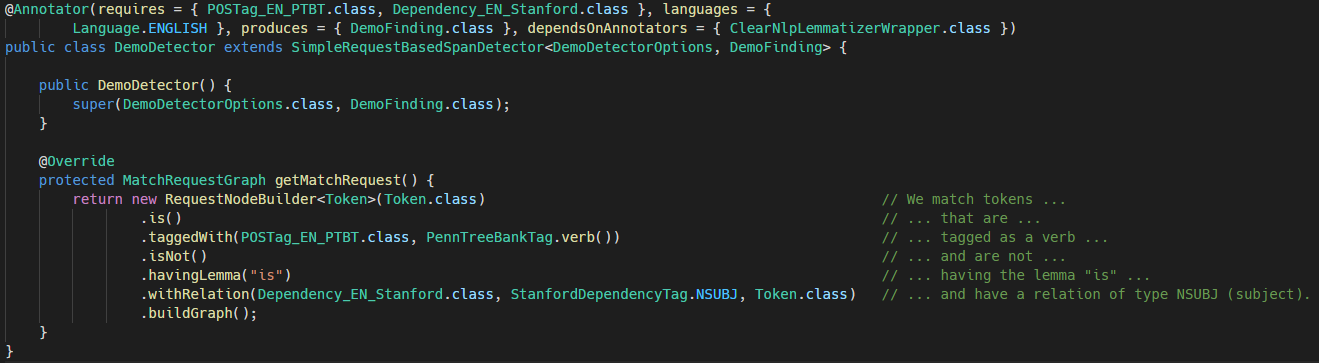
The following example detects verbs that are not any form of “is”, and the corresponding subject of the sentence. Intuitively, the detector marks “who does what”. For example, in the sentence “The red fox jumps over the tree.” the detector would mark “fox jumps”.
The red fox jumps over the tree.
A cat usually eats mice.
This example illustrates the annotations.
But above all, we write our query down in a declarative way: We just write which pattern the text should fulfil and holmes does the rest. Note that we are using lemmatization, pos tagging, and dependency parsing for this task, but we do not need to do any cumbersome configuration, data-manipulation or anything like that.
@Annotator(requires = { POSTag_EN_PTBT.class, Dependency_EN_Stanford.class }, languages = {
Language.ENGLISH }, produces = { DemoFinding.class }, dependsOnAnnotators = { ClearNlpLemmatizerWrapper.class })
public class DemoDetector extends SimpleRequestBasedSpanDetector<DemoDetectorOptions, DemoFinding> {
public DemoDetector() {
super(DemoDetectorOptions.class, DemoFinding.class);
}
@Override
protected MatchRequestGraph getMatchRequest() {
return new RequestNodeBuilder<Token>(Token.class) // We match tokens ...
.is() // ... that are ...
.taggedWith(POSTag_EN_PTBT.class, PennTreeBankTag.verb()) // ... tagged as a verb ...
.isNot() // ... and are not ...
.havingLemma("is") // ... having the lemma "is" ...
.withRelation(Dependency_EN_Stanford.class, StanfordDependencyTag.NSUBJ, Token.class) // ... and have a relation of type NSUBJ (subject).
.buildGraph();
}
}
String text = "The red fox jumps over the tree."; DemoDetector detector = new DemoDetector(); TextAnalysis analysis = new TextAnalysis(Collections.singletonList(detector), Language.ENGLISH); ACS acs = analysis.analyze(text); List<DemoFinding> findings = acs.getCollection(DemoFinding.class).asList();
There is a plethora of other constructs in our query language, like loops, regex-like stars, optional conditions. These are all covered in our fine manual.
How to Obtain Holmes
- Contact Sebastian at sebastian.eder@qualicen.de and get a copy of the holmes library. We’re happy to give you evaluation licences.
- Read our fine manual: Holmes is very well documented with Tutorials and, of course, code comments.
- Import it into your own software projects and start hacking!
Wrap Up
We tackle the major issues with state-of-the-art NLP-libraries by providing an intuitive and precise query language for text with NLP-features. With this, we allow for mining text and interpret the results of NLP-tasks. With the automated pipeline generation, we take the burden of you to identify the prerequisites of some NLP tasks and make them run. Additionally, you do not need to convert the result data of one task to fit the next. All of this allows you for creating custom NLP-tasks correctly and in no time.
With holmes, you are ready to easily leverage the power of state-of-the-art NLP in you modern applications.



Sorry, the comment form is closed at this time.
Pingback: Happy Birthday, Qualicen! – Qualicen
26/11/2020Pingback: The Great Pipeline – How Holmes Selects its Annotators – Qualicen
30/11/2021