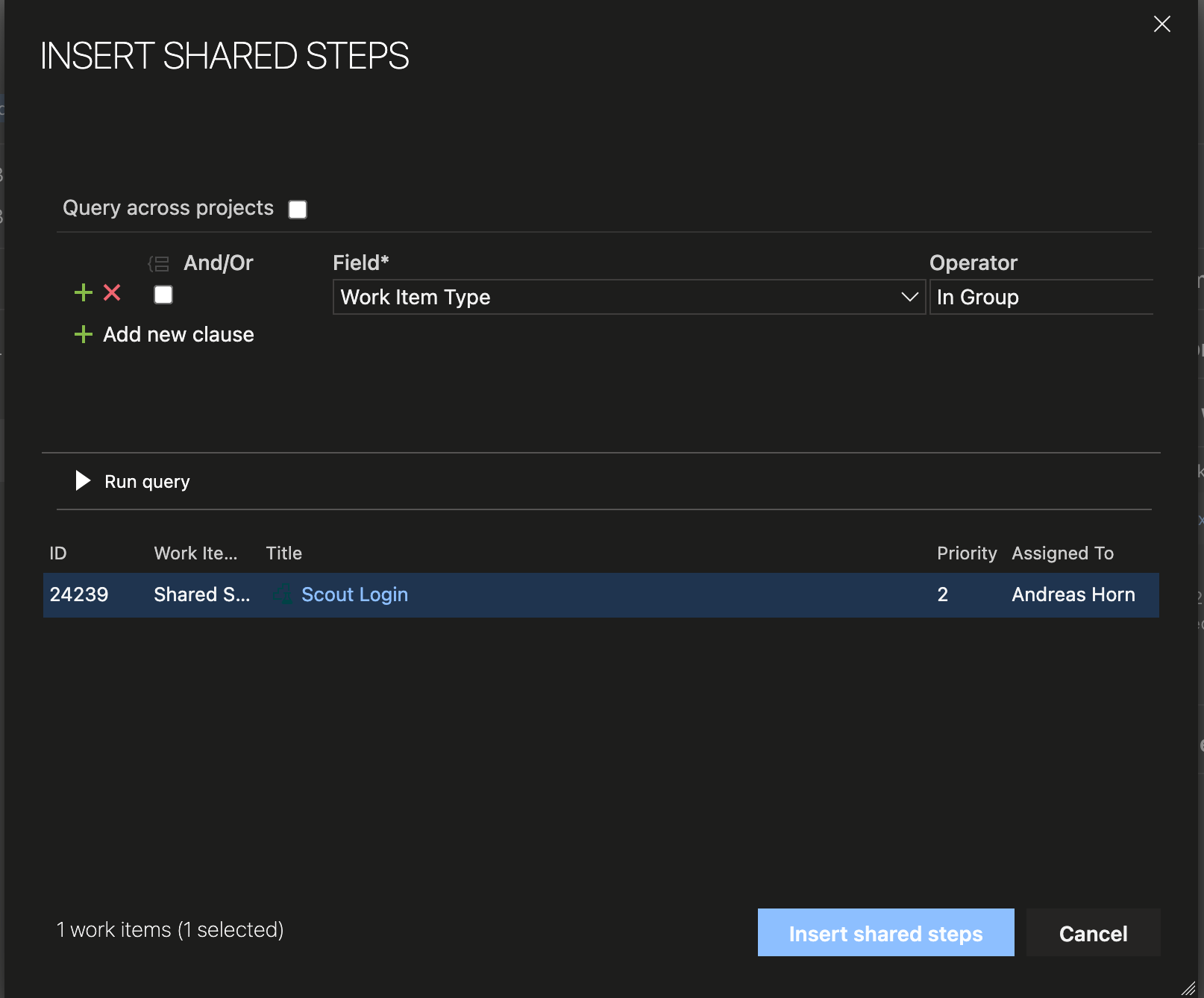
How to Reuse Test Steps and Test Cases in Azure DevOps
Do you know how many times you changed a test case in Azure DevOps and did not know that there were 2 other test cases with the same steps (so called “clones”), that you should have changed, too? Do you
Release: Qualicen Scout 5.4-1
We are proud to announce the latest release of our automated quality analysis tool: Scout 5.4-1. In this release we incorporated many new features, and improved existing ones. In this blogpost we provide a brief overview of the most

The Incredible Potential of Text Analytics – The Use Cases Explained.
New advances in text analytics make the tech news nearly every week, most prominently IBM Watson, but also more recently AI approaches such as ELMo or BERT. And now it made world news with the pandemic caused by the Covid-19 virus, with the white house requesting help via NLP.
Text Analytics and Natural Language Processing (NLP) deal with all types of automatic processing of texts and is often built on top of machine learning or artificial intelligence approaches. The idea of this article is not to explain how text analytics works, but instead to explain what is possible.
BRAND NEW!!! Test Smell Plugin for VSTS DevOps
Test Smell Detection improves your manual test cases. The automatic detection of test smells helps making your test suite easy to understand and easy to maintain. In addition, the automatic detection also leads to consistent reproducible test results. The best way to find test smells is our Qualicen Scout. Scout can detect test smells in textual test descriptions automatically. Configured once, it immediately shows where you can improve your test descriptions. What kind of improvements you ask? Well, there is a wide variety of so called "Test Smells" Scout can automatically detect! Test smells are words, phrases, or language constructs that are not good for your test quality. For example, ...
- ambiguous phrases in your test descriptions (a threat to reproducible test results).
- sentences/paragraphs that are difficult to comprehend (prevents that your colleagues ask: "eh, what?")
- tests having multiple flows (shouldn’t a test focus on just one case?).
- steps that have been copied between test cases (super annoying to keep in sync when things change).
- and many more ...
Conditionals: Why you should avoid these two letters for better test case execution
At Qualicen, it's often my job to check other people's system test cases and tell the team what I think about these tests. So what do I look for? Well, in principle it is simple: After tests are written down, they are "only" executed and maintained. So this is where tests can be bad and I try to spot things that make execution and maintenance harder. For the maintenance, the largest problem here are clones, which we covered in our last blog post. For the test execution, the main problem that you want to avoid is that different testers test different things. This is called ambiguity and comes in many tastes. In this blog post, I want to explain what is structural ambiguity and why it is bad, and this way help you to create better test cases.
(Scroll to the summary, if you don't care about the details) ;)
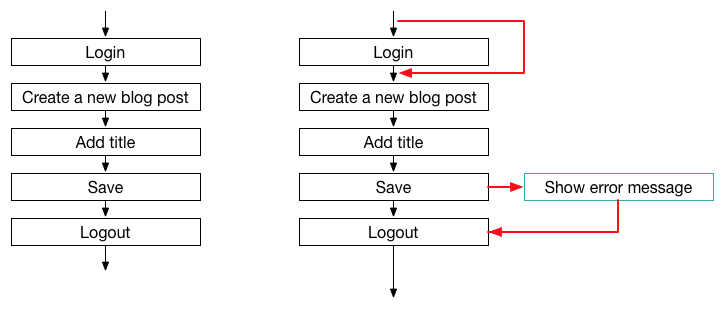
Ambiguous test flow
The problem for test execution that I want to discuss here, is an ambiguous test flow. This means, that for a single test case, there are multiple paths that a tester can follow when she executes the test. Let’s look at an example.
[caption id="attachment_145" align="alignleft" width="810"] A simple, straight-forward natural language system test case.[/caption]
A simple, straight-forward natural language system test case.[/caption]

Why test clones mess with your test quality – And how to avoid them
I recently reviewed a manual test suite of one of our customers. One of the first things I check very early in a review is the number of clones (i.e. duplicated parts of a test suite, usually created by copy and paste). In this recent case, I discovered that nearly 70% of the test suite is duplicated. That means, when I take some arbitrary test step, the chance is 70% that the test step is a 1:1 copy of another step. At the top of the post is a tree map that visualizes the amount of clones I found. Each rectangle represents a test, the more red a rectangle is, the bigger the amount of cloning. In my experience, cloning in test suites is the biggest problem with regard to maintainability of a test suite. Cloning causes considerable costs as the effectiveness of the test suite decreases and the effort for maintenance rockets. In this post I take a closer look on cloning in test suites. I show you an example to illustrate how clones can look like and explain where clones come from. Later, I give you good reasons why you should care about clones in tests and discusss strategies you can employ to avoid or at least deal with clones.